super flexible, layered plot specification (see Wickham 2008), based on an underlying “grammar of graphics” (Wilkinson 2005, originally published in 1999)
theme system for polishing plot appearance
lots of additional functionality thanks to extensions
1. data – in tidy format + define aesthetics (how variables map onto a plot e.g. axes, shape, color, size) 2. geometric objects (aka geoms) – define the type of plot(s)
Then these:
3. statistical transformations – algorithm used to calculate new values for a graph 4. position adjustments – control the fine details of position when geoms might otherwise overlap 5. coordinate system – change what x and y axes mean (e.g. Cartesian (default), polar, flipped) 6. facet – create subplots that each display one subset of the data
Enhance communication using additional layers
1. labels – add / update titles, axis / legend labels 2. annotations – add textual labels (e.g. to highlight specific data points or trend lines, etc.) 3. scales – update how the aesthetic mappings manifest visually (e.g. colors scales, axis ticks, legends) 4. themes – customize the non-data elements of your plot 5. layout – combine multiple plots into the same graphic
The {tidyverse} is an “opinionated” set of packages – meaning they share similar philosophies, grammar, and data structures – that are incredibly useful for data wrangling, cleaning, and manipulation (and of course, visualization).
Check out the tidyverse website to learn more about each of these packages
We’ll start by exploring the relationship between penguin bill length and bill depth. For this example, we’ll focus on understanding the following layers of a ggplot (bolded):
Graphic layers:
1. data – in tidy format + define aesthetics (how variables map onto a plot e.g. axes, shape, color, size) 2. geometric objects (aka geoms) – define the type of plot(s) 3. statistical transformations – algorithm used to calculate new values for a graph 4. position adjustments – control the fine details of position when geoms might otherwise overlap 5. coordinate system – change what x and y axes mean (e.g. Cartesian (default), polar, flipped) 6. facet – create subplots that each display one subset of the data
“Enhancing communication” layers:
1. labels – add / update titles, axis / legend labels 2. annotations – add textual labels (e.g. to highlight specific data points or trend lines, etc.) 3. scales – update how the aesthetic mappings manifest visually (e.g. colors scales, axis ticks, legends) 4. themes– customize the non-data elements of your plot 5. layout – combine multiple plots into the same graphic
Initialize a plot object
Initialize your plot object using ggplot() – this creates a graph that’s primed to display the penguins data set, but empty since we haven’t told ggplot how to map our data onto the graph yet (in other words: we haven’t told ggplot what variables to display and where, as well as what type of plot to create):
The mapping argument defines how variables in your data set are mapped to visual properties (aesthetics) of your plot. Here, we specify which variables map to our x and y axes:
library(palmerpenguins)library(tidyverse)ggplot(data = penguins, mapping =aes(x = bill_length_mm, y = bill_depth_mm))
Omitting argument names
The data and mapping arguments are often not explicitly written in ggplot(), as in the example below (makes for more concise code):
ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm))
Define a geom to represent data
Next, we’ll layer on a geometric object (aka geom) that our plot will use to represent our penguin data. There are many geoms (geom_*()) that are built into {ggplot2} already (and more when you use extension packages). To create a scatter plot:
ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm)) +geom_point()
Use color to differentiate species
If we’d like to represent species using another aesthetic (e.g. color, shape, size), we need to modify our plot’s aesthetic (i.e. inside aes()) – any time we want to modify the appearance of our plotted data based on a variable in our data set, we do so within aes(). This process is known as scaling. A legend will automatically be added to indicate which values (in this case, colors) correspond to which level of our variable (in this case, species):
ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm, color = species)) +geom_point()
We can also map our own colors
Here, we use scale_color_manual() to update the colors of our data points. Colors will be mapped from the levels in our data (i.e. Adelie, Chinstrap, Gentoo) to the order of the aethetic values supplied ("darkorange","purple","cyan4"):
ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm, color = species)) +geom_point() +scale_color_manual(values =c("darkorange","purple","cyan4"))
Use color to describe a continuous variable
In the previous example, we mapped color to a categorical variable (species). We can also map color to continuous variables (e.g. body_mass_g):
ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm, color = body_mass_g)) +geom_point() +scale_color_gradient(low ="#132B43", high ="#F7DD4C")
What if we just want to color all points the same?
Do so within the corresponding geom_*() and outside of the aes() function! Color is no longer being mapped to a variable.
ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm)) +geom_point(color ="blue")
Defining data & mappings in geom_*()
You can also define the data and mapping layers within a geom_*() (i.e. locally) rather than in ggplot() (i.e. globally) – this is helpful if you plan to have multiple geoms with different mappings (e.g. you’re plotting data from multiple data frames). You must include the data and mapping argument names if you specify them out of order (see documentation):
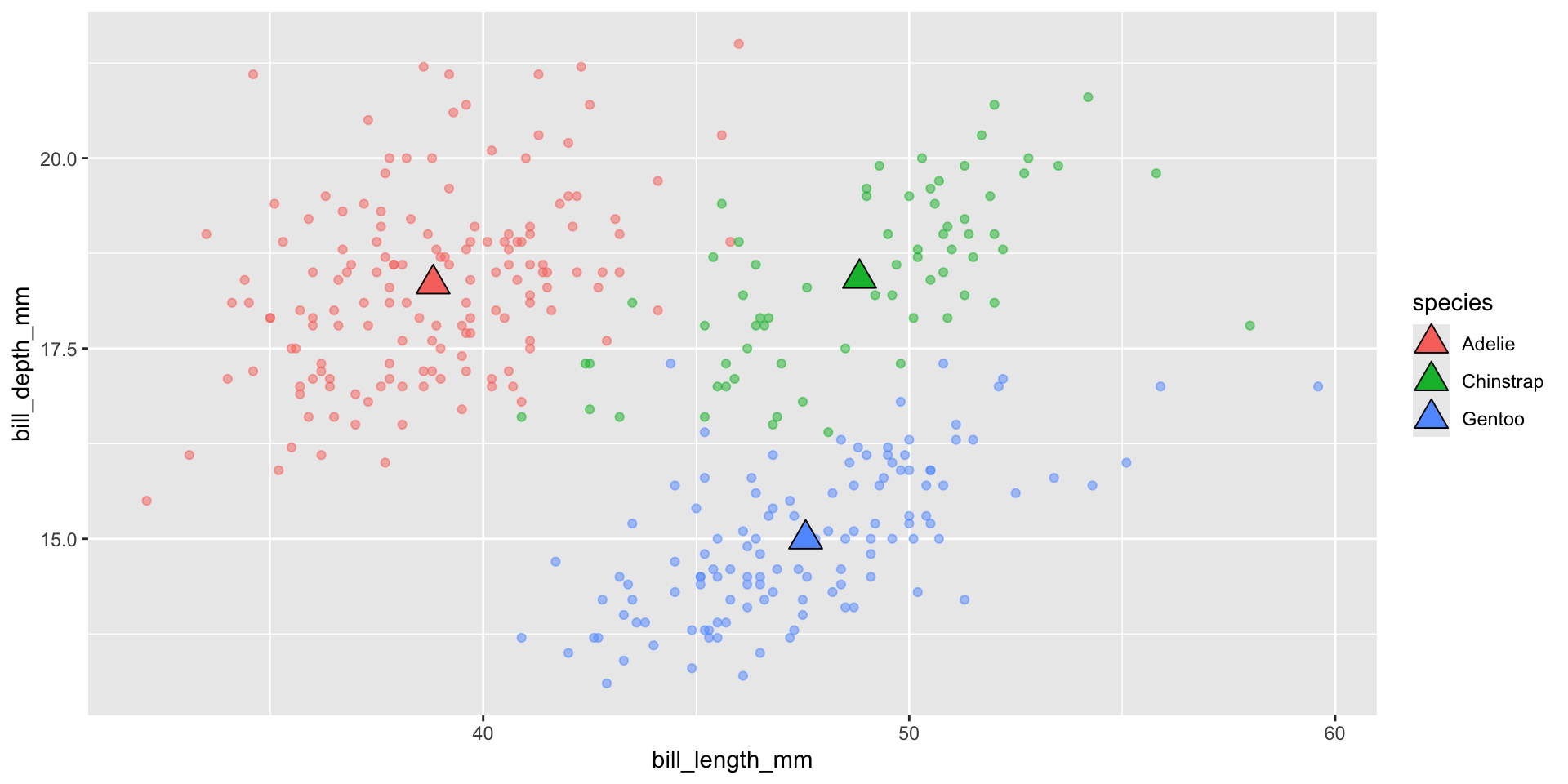
# create a separate penguins_summary df ----penguins_summary <- penguins |>drop_na() |>group_by(species) |>summarize(mean_bill_length_mm =mean(bill_length_mm),mean_bill_depth_mm =mean(bill_depth_mm) )# create ggplot with layers from different dfs ----ggplot() +geom_point(data = penguins, mapping =aes(x = bill_length_mm, y = bill_depth_mm, color = species), alpha =0.5) +geom_point(data = penguins_summary, mapping =aes(x = mean_bill_length_mm, y = mean_bill_depth_mm, fill = species),size =5, shape =24)
Mapping color at a local level
You may also separately map color at a local (i.e. within a specific geom) rather than global (i.e. within ggplot()) level:
ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm)) +geom_point(aes(color = species))
Why map locally?
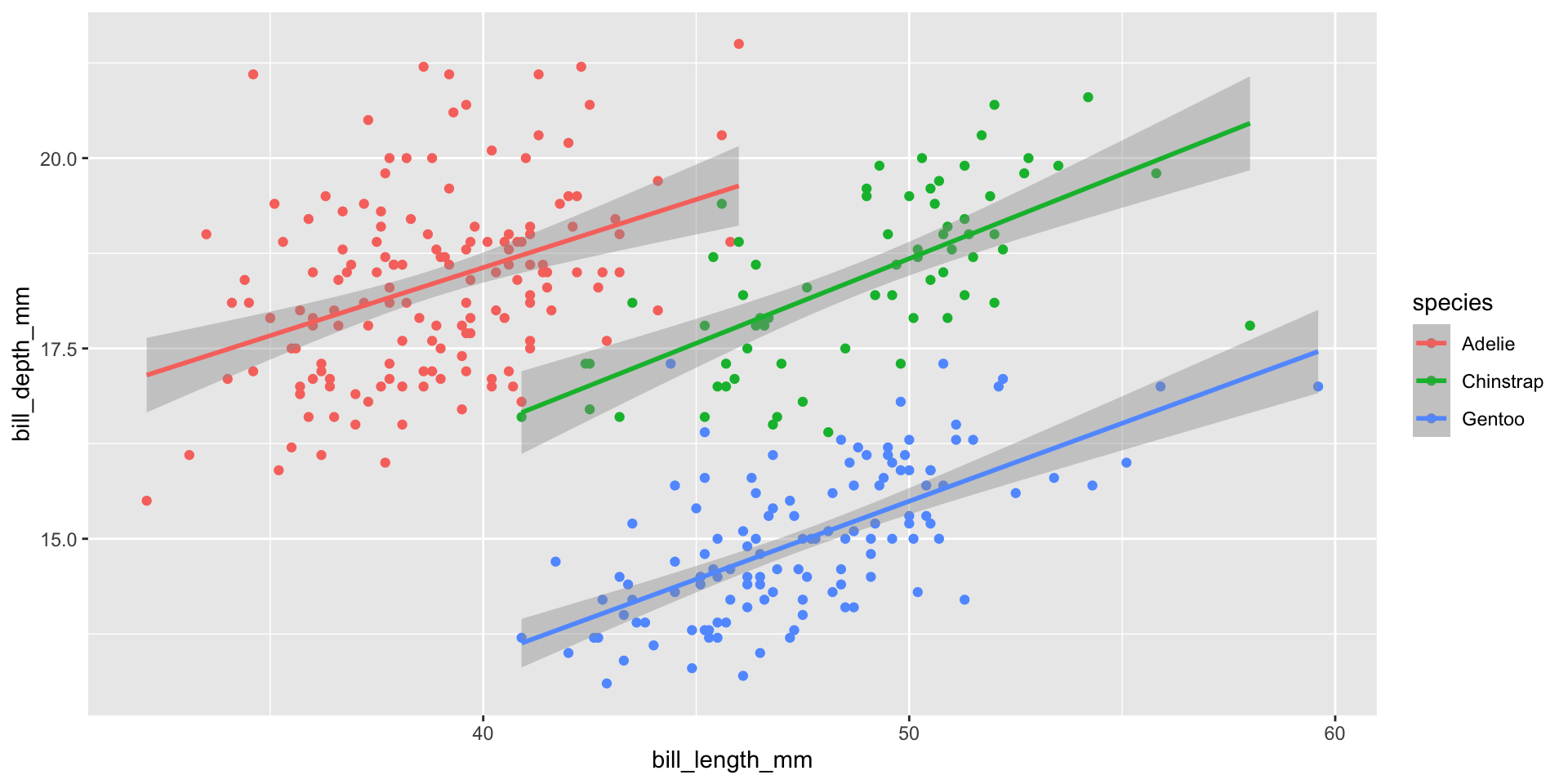
Here, we use geom_smooth() to add a best fit line (based on a linear model, using method = "lm") to our plot:
Global mappings are passed down to each subsequent geom layer. Therefore, the color = species mapping is also passed to geom_smooth(), resulting in a best fit line for each species.
ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm, color = species)) +geom_point() +geom_smooth(method ="lm")
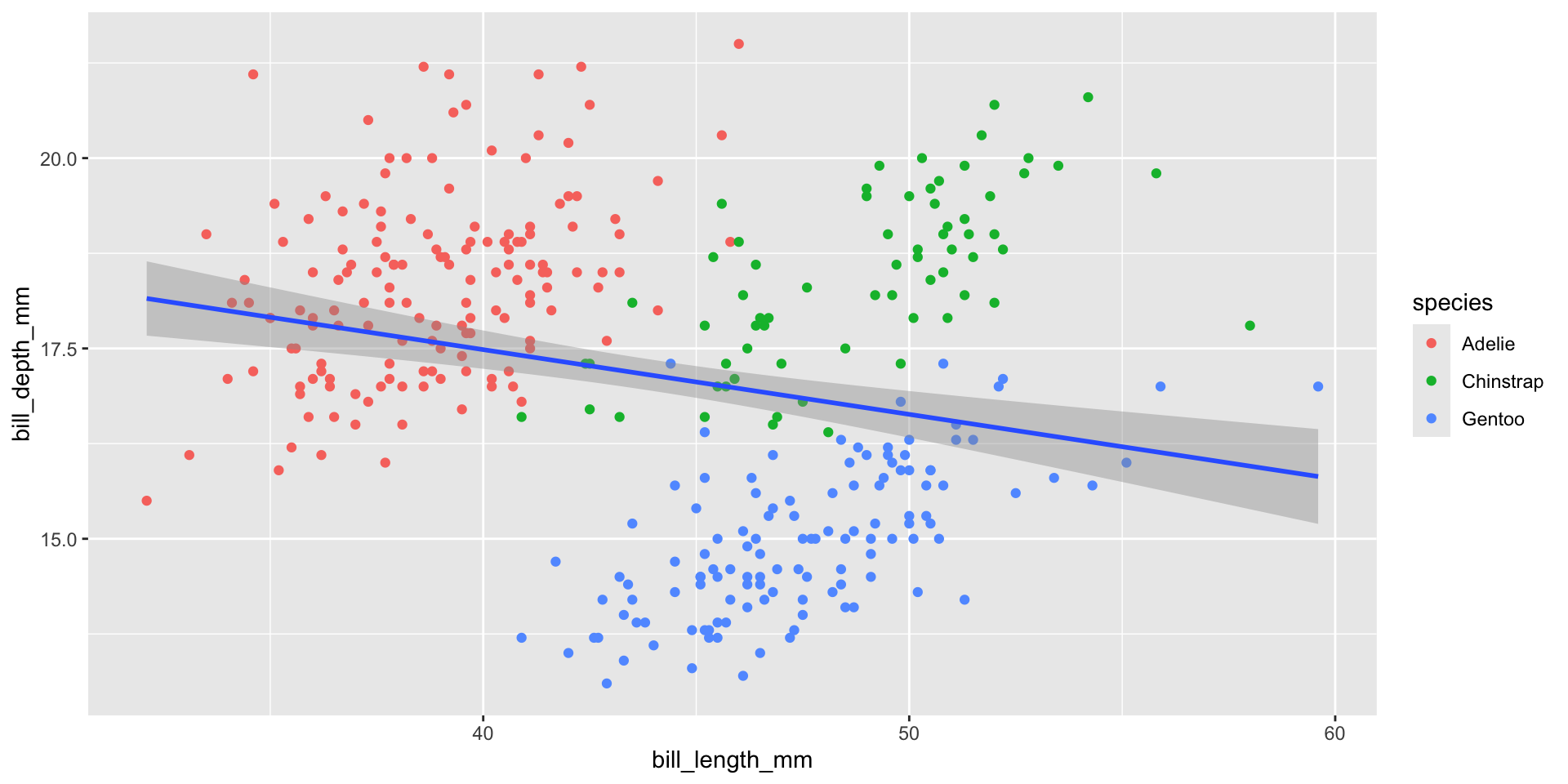
Local mappings (e.g. within geom_point()) only apply to that particular layer. Therefore, the color = species mapping is only applied to geom_point(), and geom_smooth() fits a best fit line to the entire data set.
Lastly, you can also pipe (using %>% or |>) directly from a data frame into a ggplot() call (we’ll use more of this in future lessons) – this is useful if you need to do a bit of data wrangling first, but don’t want to create a whole new data frame. When doing so, omit the data argument from ggplot():
penguins |>filter(species =="Gentoo") |>ggplot(aes(x = bill_length_mm, y = bill_depth_mm)) +geom_point()
Plot #2
In this next example, we’ll explore penguin species counts. For this example, we’ll focus on understanding the following layers of a ggplot (bolded):
Graphic layers:
1. data – in tidy format + define aesthetics (how variables map onto a plot e.g. axes, shape, color, size) 2. geometric objects (aka geoms) – define the type of plot(s) 3. statistical transformations – algorithm used to calculate new values for a graph 4. position adjustments – control the fine details of position when geoms might otherwise overlap 5. coordinate system – change what x and y axes mean (e.g. Cartesian (default), polar, flipped) 6. facet – create subplots that each display one subset of the data
“Enhancing communication” layers:
1. labels – add / update titles, axis / legend labels 2. annotations – add textual labels (e.g. to highlight specific data points or trend lines, etc.) 3. scales – update how the aesthetic mappings manifest visually (e.g. colors scales, axis ticks, legends) 4. themes– customize the non-data elements of your plot 5. layout – combine multiple plots into the same graphic
Initialize + map aesthetics + define geom
Similar to our first scatterplot, we start by initializing our plot object with data, mapping our aesthetics, and defining a geometric object:
ggplot(penguins, aes(x = species)) +geom_bar()
What is a statistical transformation?
Some geoms, like scatterplots, plot the raw values of your data set. Other geoms, like bar charts, histograms, boxplots, smoothers, etc. calculate new values to plot.
Each point on our scatterplot represents a raw observation value (one point = one penguin)
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g, color = species)) +geom_point()
Each bar represents a species count (note the y-axis, count, which is not a variable in our penguins data set)
ggplot(penguins, aes(x = species)) +geom_bar()
The default stat for geom_bar() is “count”
Every geom has a default stat – meaning you can typically use geoms without worrying about the underlying statistical transformation.
The default statistical transformation used in geom_bar() is count, which first groups our categorical variable (species), then calculates a count for each unique level (Adelie, Chinstrap, Gentoo).
ggplot(penguins, aes(x = species)) +geom_bar(stat ="count") # you don't need to explicitly include `stat = "count"` since it's the default
We can override the default stat
Let’s say we have a data frame with calculated count values (e.g. penguins_summary) that we’d like to plot using geom_bar(). We can change stat = "count" (default) to stat = "identity" to generate bar heights based off the “identity” of values in the n column of penguin_summary.
# new summary df which calculates # of observations (rows) for each spp ----penguin_summary <- penguins |>count(species) # bar plot where heights of bars are generated based of "identity" of values ----ggplot(penguin_summary, aes(x = species, y = n)) +geom_bar(stat ="identity")
We can override the default stat mapping
Now let’s say we’d like to display the same bar chart with y-axis values as proportions, rather than counts. We can override the default mapping of transformed variables to aesthetics with:
ggplot(penguins, aes(x = species, y =after_stat(prop), group =1)) +geom_bar()
first, stat = "count" counts the number of occurrences in each category (here, species)
next, specifying y = after_stat(prop) tells ggplot to calculate the proportion of each species count relative to the total count (delayed until after counts have been computed)
group = 1 ensures that proportions are calculated across all species – default behavior of geom_bar() is to group by the x variable to separately count the number of rows in each level (Adelie, Chinstrap, Gentoo), but we actually need to know how many total penguins there are in the data set in order to calculate proportions
What is a position adjustment?
Position adjustments apply minor tweaks to the position of elements to resolve overlapping geoms. For example, let’s say we would like to visualize penguin counts by species (bar height) and by island (color) using our bar chart from earlier. We could add the fill aesthetic:
ggplot(penguins, aes(x = species, fill = island)) +geom_bar()
The default position for geom_bar() is “stack”
Every geom has a default position. The default position used in geom_bar() is stack, which stacks bars on top of one another, based on the fill value (here, that’s island):
ggplot(penguins, aes(x = species, fill = island)) +geom_bar(position ="stack") # you don't need to explicitly include `position = "stack"` since it's the default
Alternative position adjustments for geom_bar()
Below are a few position options available for use with geom_bar():
position = "fill" creates a set of stacked bars but makes each set the same height (easier to compare proportions across groups)
ggplot(penguins, aes(x = species, fill = island)) +geom_bar(position ="fill")
position = "dodge" places overlapping bars directly beside one another (easier to compare individual values)
ggplot(penguins, aes(x = species, fill = island)) +geom_bar(position ="dodge")
Alternatively, use position = position_*()
Instead of position = "X", you can use functions to update and further adjust your geom’s positions. Here, we’ll use position_dodge2() to also ensure the widths of each of our bars are equal:
ggplot(penguins, aes(x = species, fill = island)) +geom_bar(position =position_dodge2(preserve ="single"))
What is a coordinate system?
A Coordinate System is a system that uses one or more numbers (coordinates), to uniquely determine the position of points or other geometric elements. By default, ggplots are constructed in a Cartesian coordinate system, consisting of a horizontal x-axis and vertical y-axis.
ggplot(penguins, aes(x = species)) +geom_bar() +coord_cartesian() # you don't need to explicitly include `coord_cartesian()` since it's the default
Changing coordinate systems
Depending on the type of data, axis label length, etc. it may make sense to change this coordinate system. Two options for our bar plot:
In this next example, we’ll explore penguin flipper lengths. For this example, we’ll focus on understanding the following layers of a ggplot (bolded):
Graphic layers:
1. data – in tidy format + define aesthetics (how variables map onto a plot e.g. axes, shape, color, size) 2. geometric objects (aka geoms) – define the type of plot(s) 3. statistical transformations – algorithm used to calculate new values for a graph 4. position adjustments – control the fine details of position when geoms might otherwise overlap 5. coordinate system – change what x and y axes mean (e.g. Cartesian (default), polar, flipped) 6. facet – create subplots that each display one subset of the data
“Enhancing communication” layers:
1. labels – add / update titles, axis / legend labels 2. annotations – add textual labels (e.g. to highlight specific data points or trend lines, etc.) 3. scales – update how the aesthetic mappings manifest visually (e.g. colors scales, axis ticks, legends) 4. themes– customize the non-data elements of your plot 5. layout – combine multiple plots into the same graphic
Initialize + map aesthetics + define geom
We’ll again start by initializing our plot object with data, mapping our aesthetics, and defining a geometric object. Note that the default statistical transformation for geom_histogram() is stat = "bin":
Just like in our scatterplot (Plot #1), we’ll modify our plot’s aesthetics (i.e. inside aes()) to color our histrogram bins according to the species variable. Unlike our scatterplot (which uses the color argument), we’ll use the fill argument to fill the bars with color (rather than outline them with color). We’ll also manually define our fill scale:
Let’s update the position of our binned bars from "stack" to "identity" and also increase the transparency (using alpha) so that we can see overlapping bars:
Update axis and legend titles and add a plot title using labs():
ggplot(penguins, aes(x = flipper_length_mm, fill = species)) +geom_histogram(position ="identity", alpha =0.5) +scale_fill_manual(values =c("darkorange", "purple", "cyan4")) +labs(x ="Flipper length (mm)", y ="Frequency", fill ="Species",title ="Penguin Flipper Lengths")
Create subplots using facets
Sometimes (particularly during the data exploration phase) it’s helpful to create subplots (i.e. separate panels) of your data. Here we use facet_wrap() to separate our data by the species variable. By default, it creates a 1 x 3 matrix of plots. We can manually specify how many rows or columns we’d like using nrow or ncol:
ggplot(penguins, aes(x = flipper_length_mm, fill = species)) +geom_histogram(position ="identity", alpha =0.5) +scale_fill_manual(values =c("darkorange", "purple", "cyan4")) +labs(x ="Flipper length (mm)", y ="Frequency", fill ="Species",title ="Penguin Flipper Lengths") +facet_wrap(~species, ncol =1)
Building a data viz is an iterative process!
We’ll spend the next two weeks learning how to build some basic fundamental charts and talking about important considerations when choosing a graphic form for presenting your data. Then, we’ll move into graphic design theory and the tools and packages in the {ggplot2} ecosystem that make it possible.