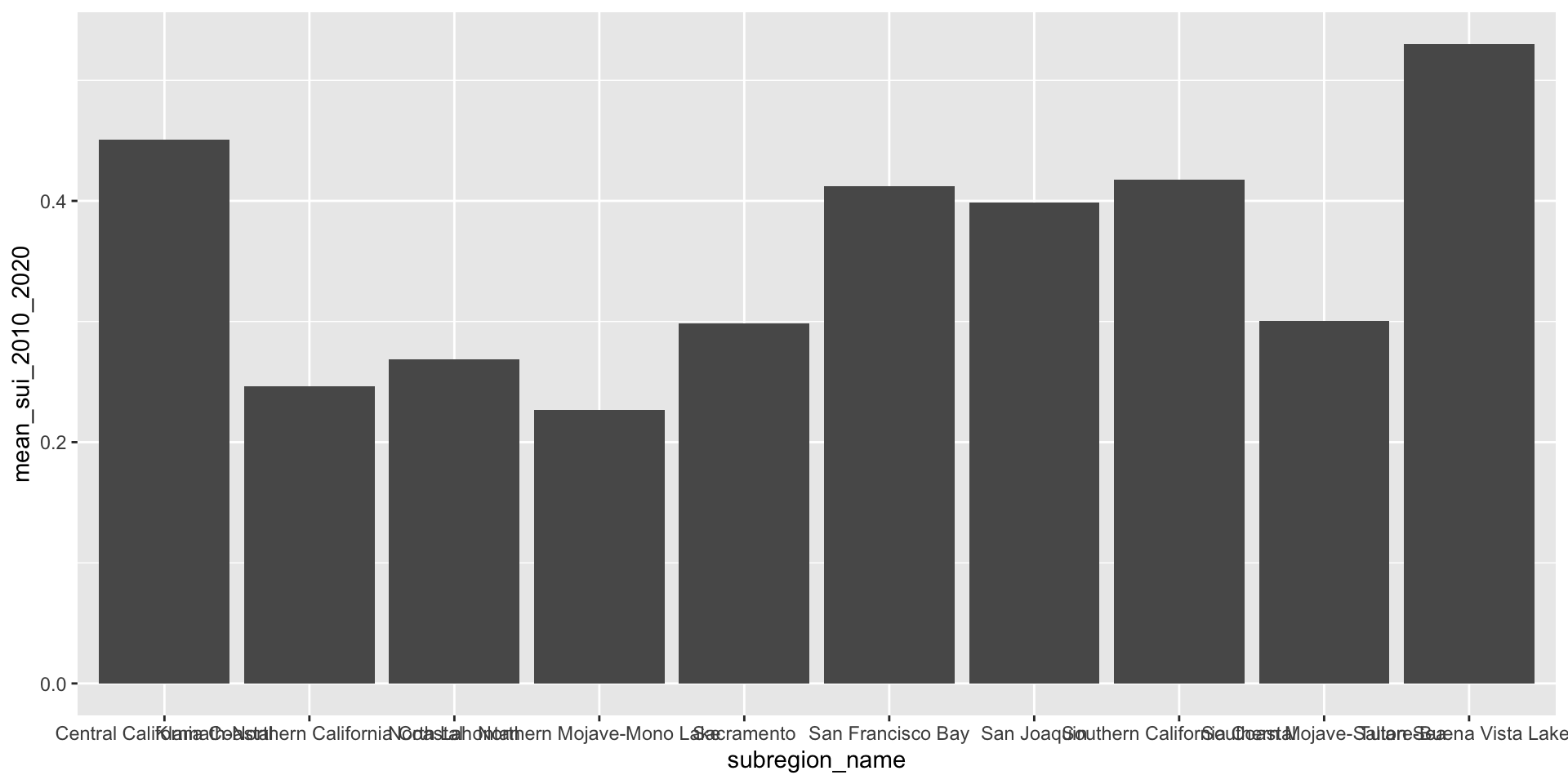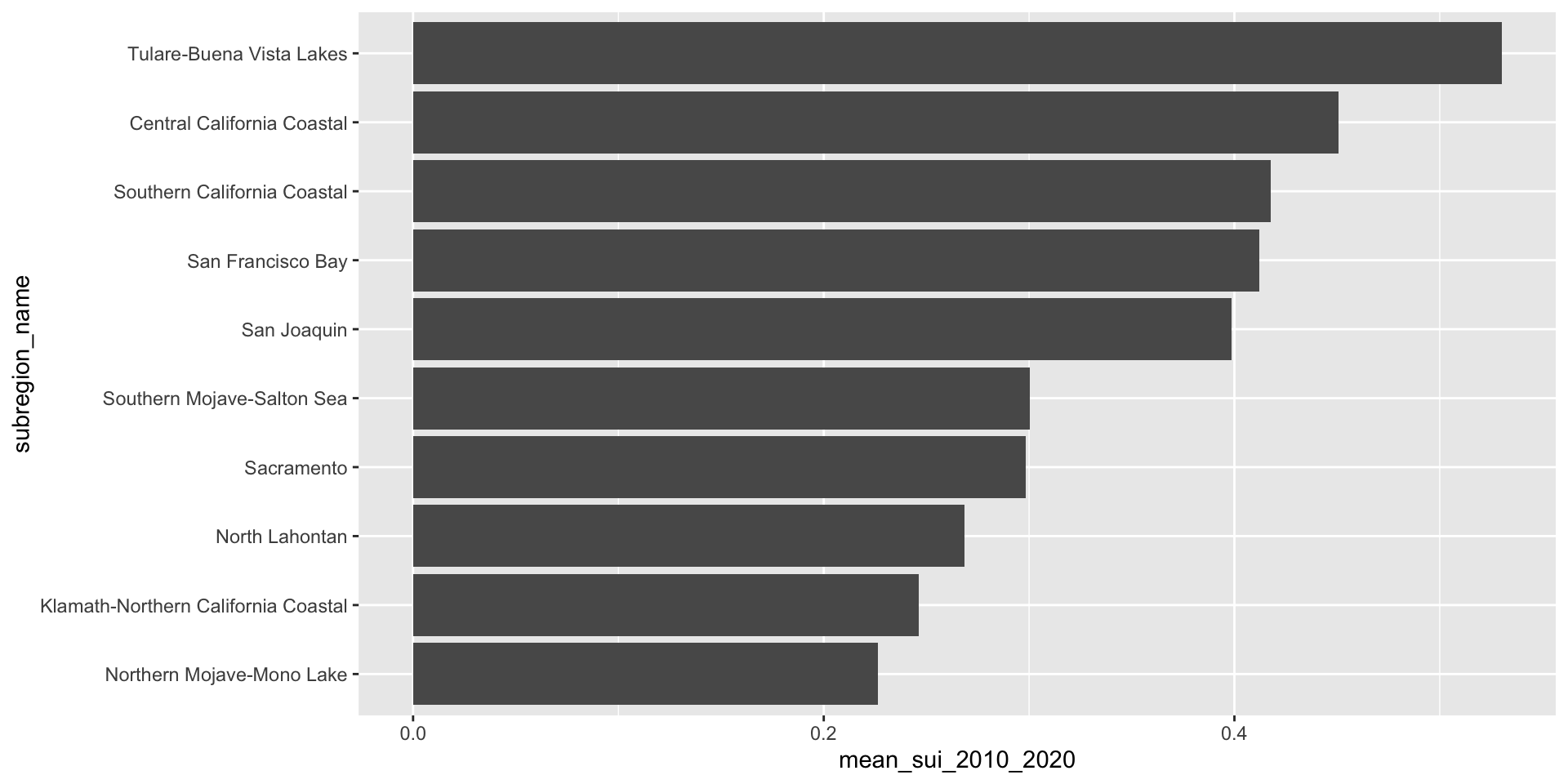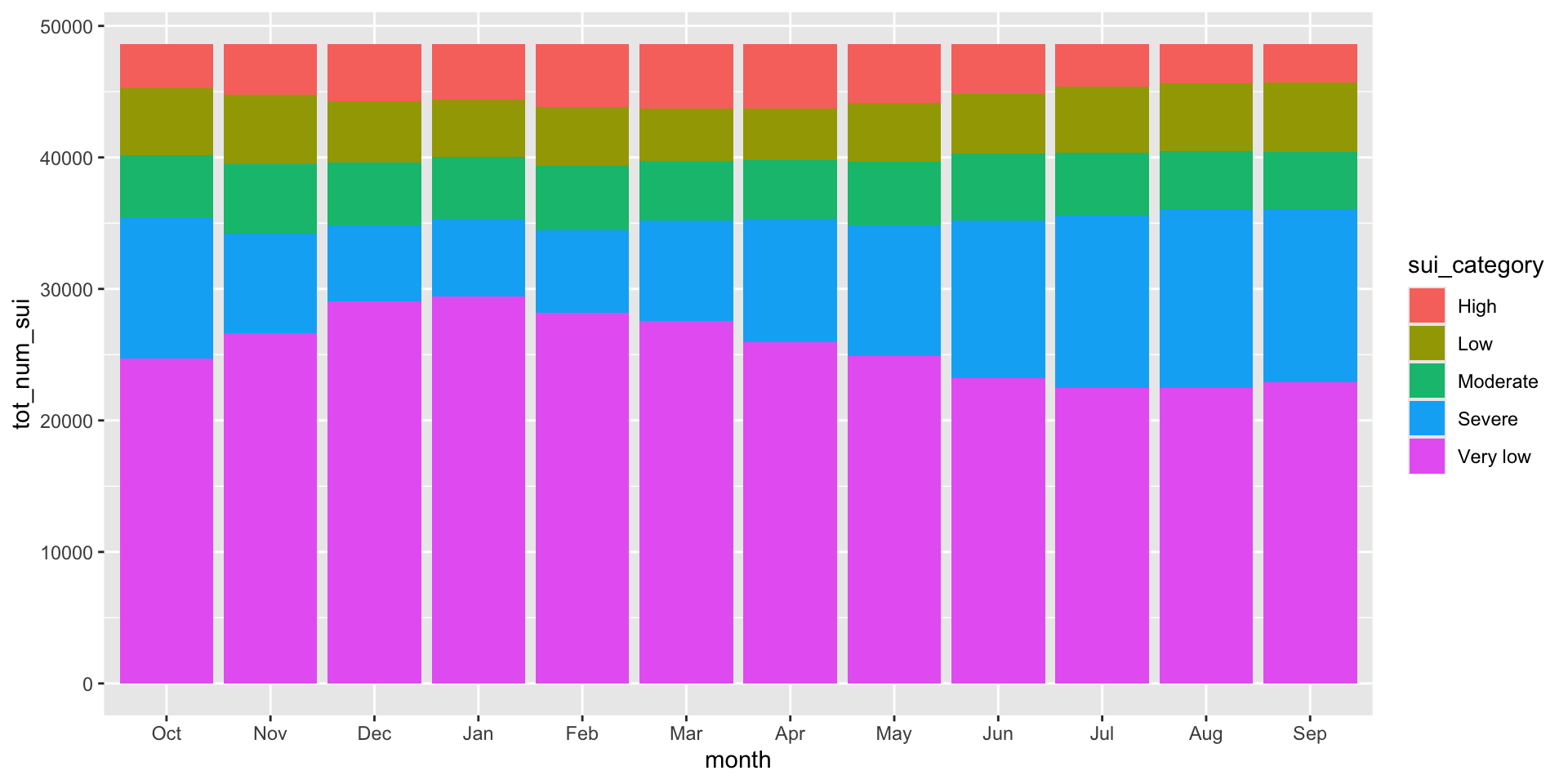
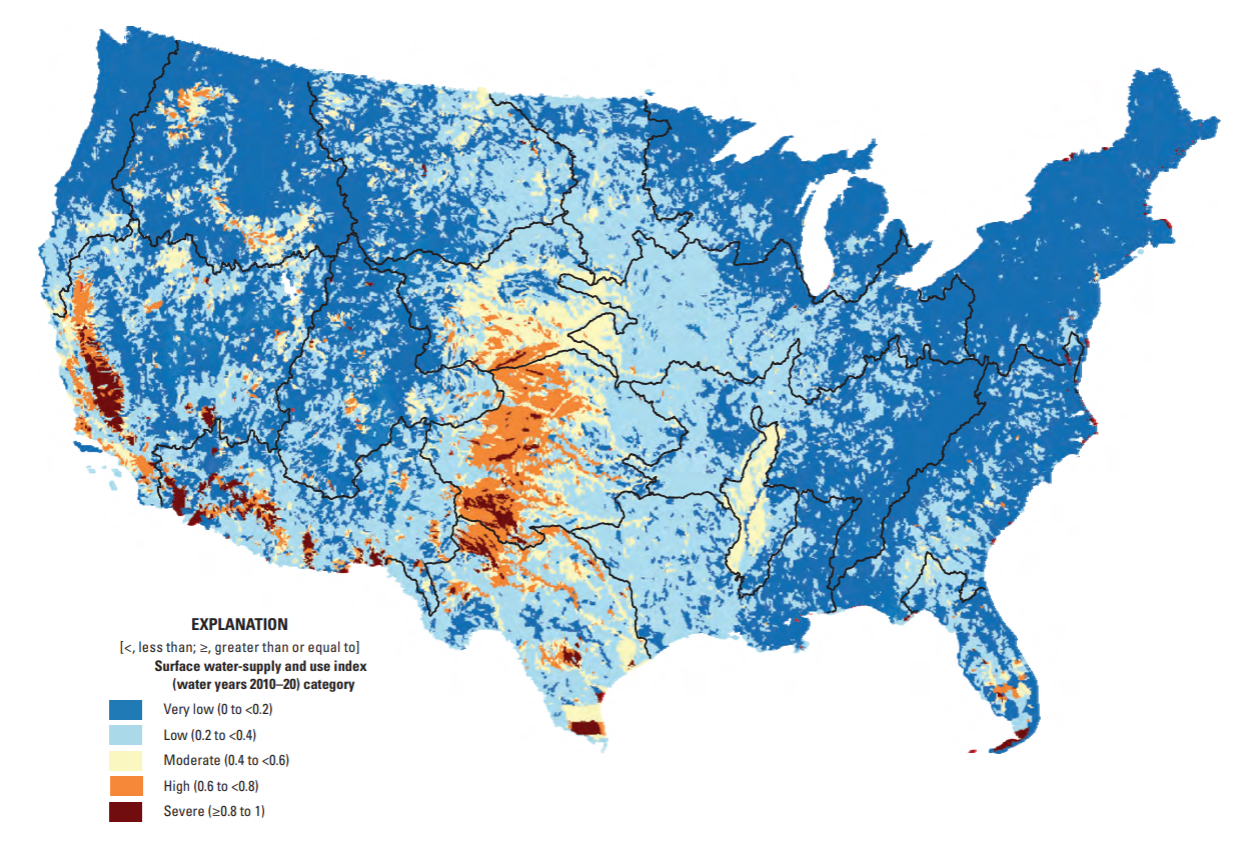
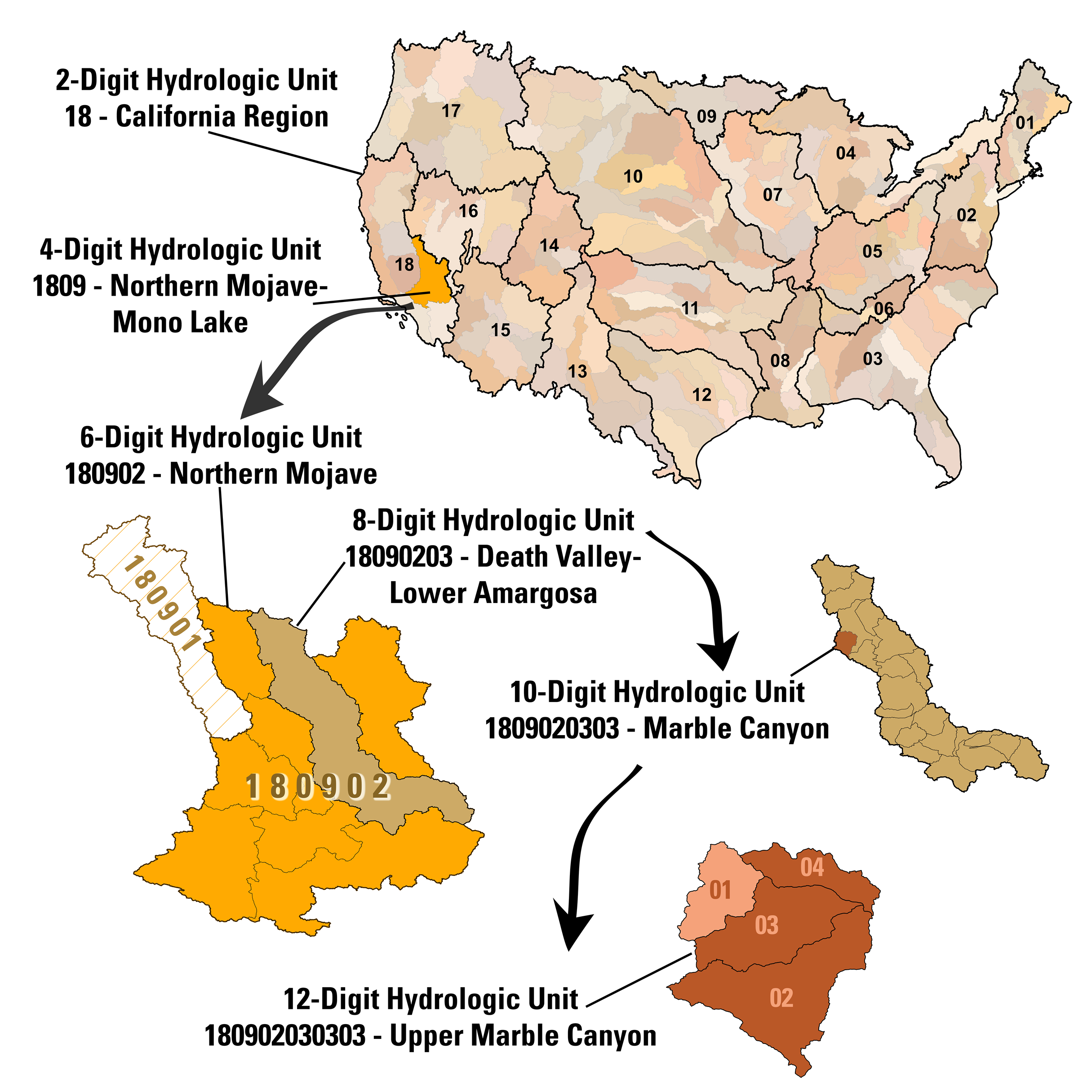
Surface water-supply and use index (SUI) by 12-digit hydrologic unit codes (HUCs) for water years 2010-2020. Source: Chapter F of the U.S. Geological Survey Integrated Water Availability Assessment—2010–20.
Showing the relationship between a numeric and categorical variable(s), i.e. comparing categorical groups based on their numeric values.
In January 2025, The U.S. Geological Survey (USGS) released its new National Water Availability Assessment (NWAA), which offers insights into water supply, demand, and quality across the U.S. The modeled water availability data that underlies the NWAA is made available through the online National Water Availability Assessment Data Companion (NWDC). Here, users can interactively subset and download data or download files containing the full spatial (conterminous US) and temporal (2010-2020) extent of the NWDC datasets.
Surface water-supply and use index (SUI) by 12-digit hydrologic unit codes (HUCs) for water years 2010-2020. Source: Chapter F of the U.S. Geological Survey Integrated Water Availability Assessment—2010–20.
For today’s lecture, we’ll download the full, integrated dataset and filter for just the California water resource region, which is represented by the 2-digit hydrologic unit code (HUC), 18. We’ll explore water availability and use across HUC 18’s ten subregions.
Let’s first look at the long-term mean Surface Water-Supply and Use Index (SUI) across the ten HUC 18 subregions. Higher SUI values indicate greater water stress. Each bar and lollipop represents the mean SUI for a given subregion, calculated by averaging all monthly SUI values from 2010–2020.
We never want to leave overlapping or super squished text (especially axis text) on our plots. Let’s give those long x-axis labels some breathing room using by reversing your axes mappings! Alternatively, you can leave your mappings as-is and apply coord_flip().
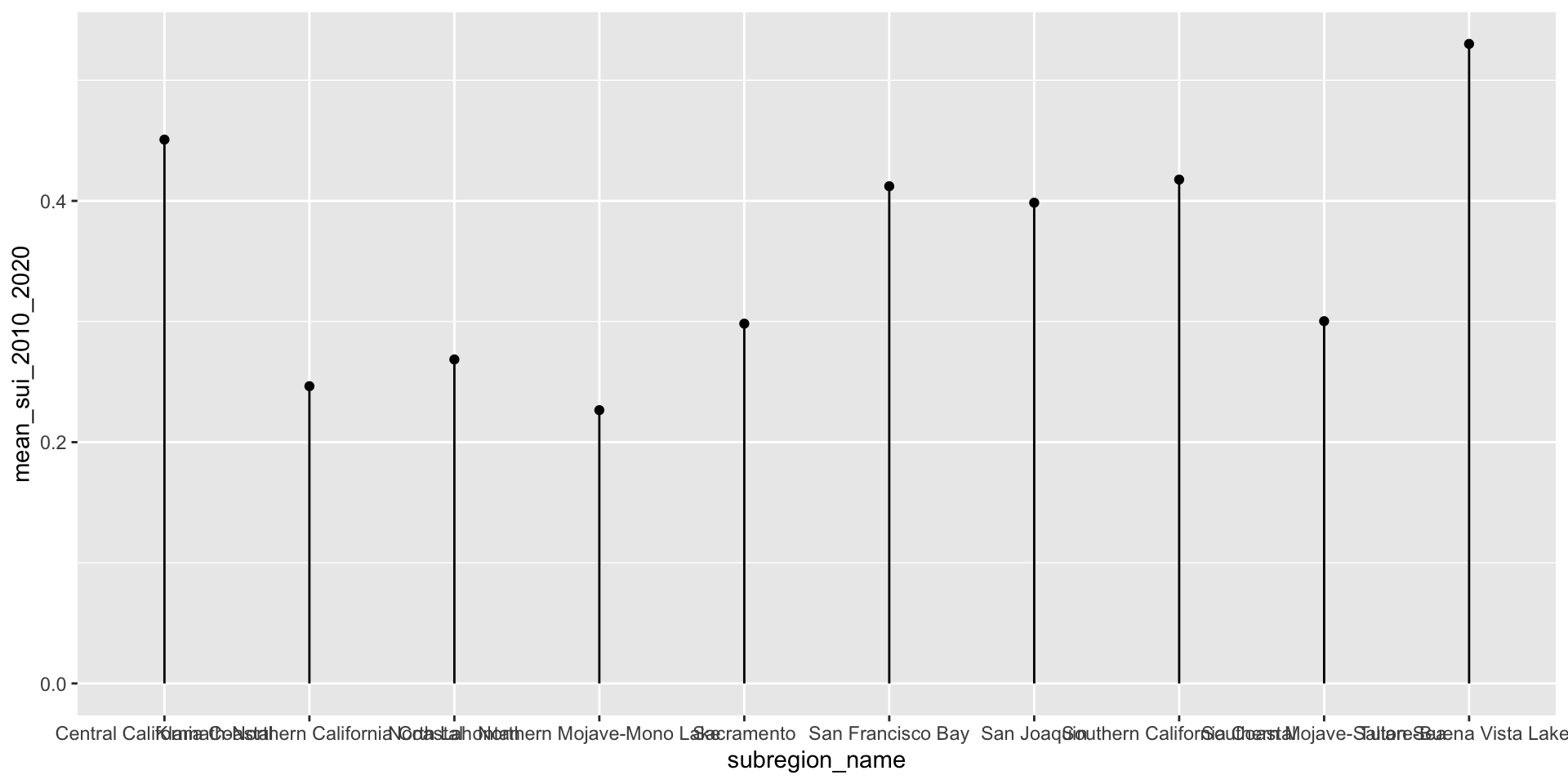
Here, we use forcats::fct_reorder() to reorder the levels of our y-axis variable, name, based on a numeric variable, mean_sui_2010_2020.
ca_region |>
group_by(subregion_name) |>
summarise(mean_sui_2010_2020 = mean(sui_frac, na.rm = TRUE)) |>
mutate(subregion_name = fct_reorder(.f = subregion_name, .x = mean_sui_2010_2020)) |>
ggplot(aes(x = mean_sui_2010_2020, y = subregion_name)) +
geom_point() +
geom_linerange(aes(xmin = 0, xmax = mean_sui_2010_2020))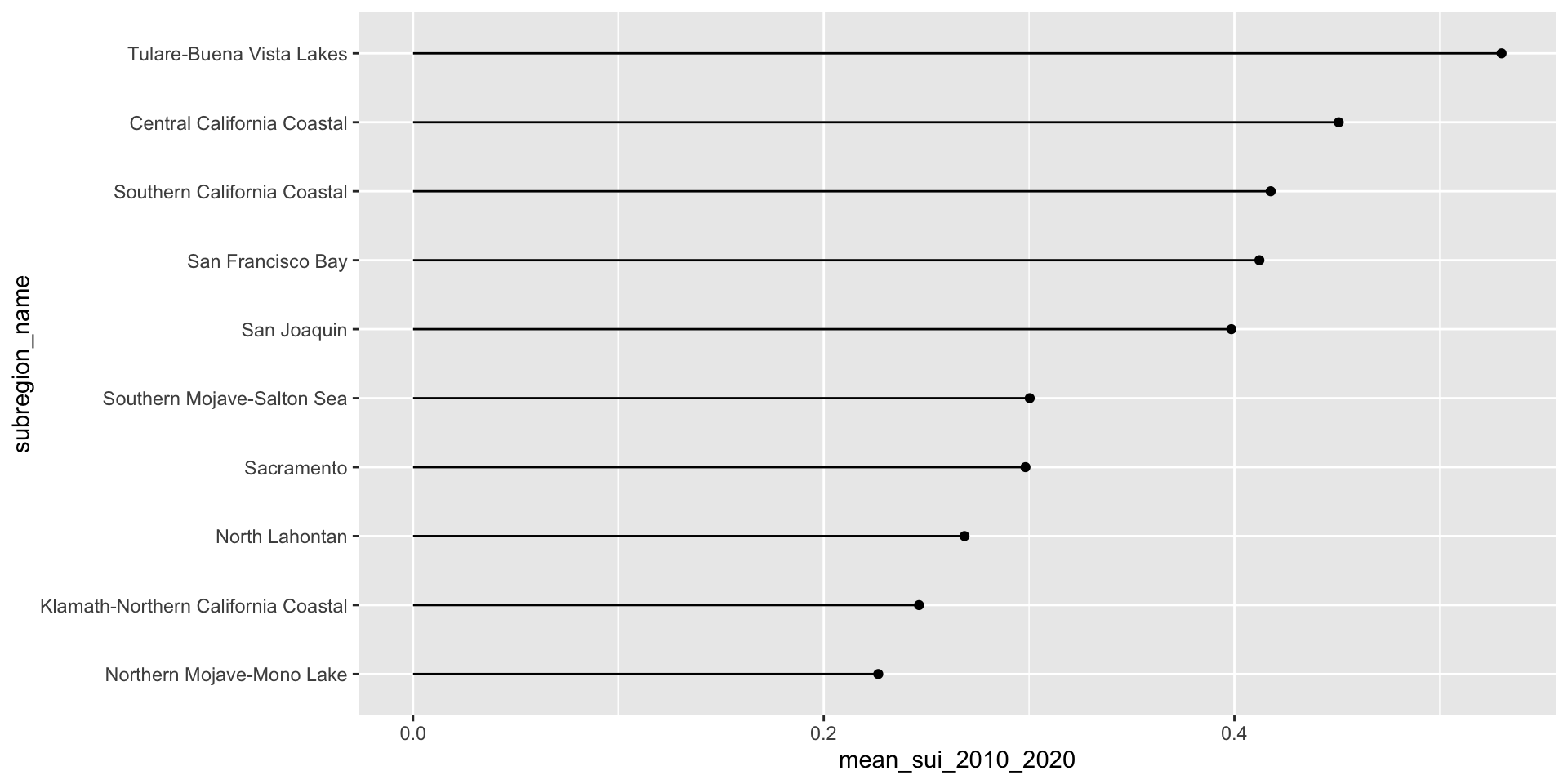
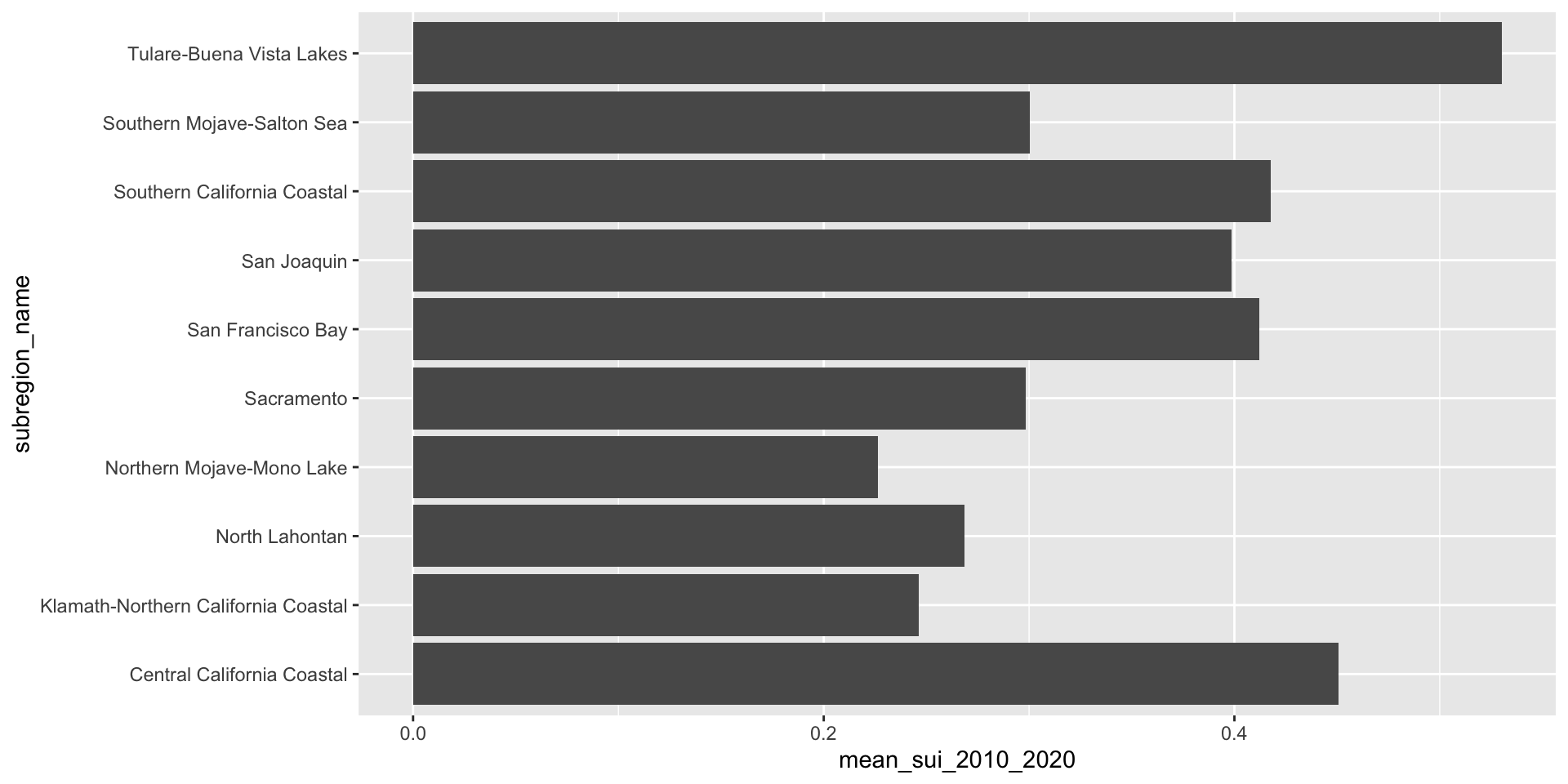
geom_text() allows us to map values from a column (here, mean_sui_2010_2020) directly onto the plot as text labels. This can be helpful if it’s important for readers to know precise values. Avoid adding if relative comparisons are enough or if it’s easy to estimate the length of a bar against its axis.
ca_region |>
group_by(subregion_name) |>
summarise(mean_sui_2010_2020 = mean(sui_frac, na.rm = TRUE)) |>
mutate(subregion_name = fct_reorder(.f = subregion_name, .x = mean_sui_2010_2020)) |>
ggplot(aes(x = mean_sui_2010_2020, y = subregion_name)) +
geom_col() +
geom_text(aes(label = round(mean_sui_2010_2020, 2)), hjust = 1.2, color = "white") 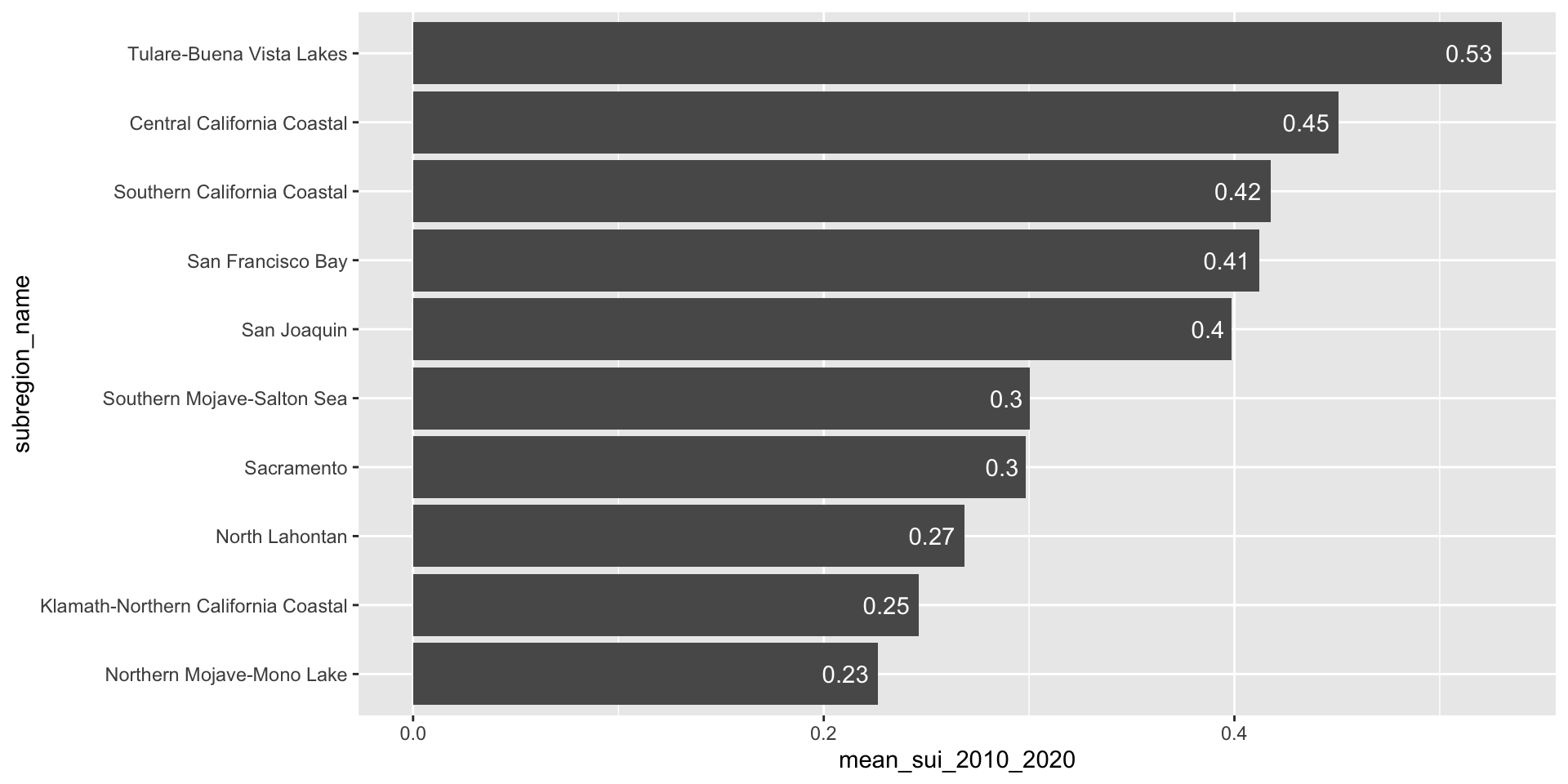
ca_region |>
group_by(subregion_name) |>
summarise(mean_sui_2010_2020 = mean(sui_frac, na.rm = TRUE)) |>
mutate(subregion_name = fct_reorder(.f = subregion_name, .x = mean_sui_2010_2020)) |>
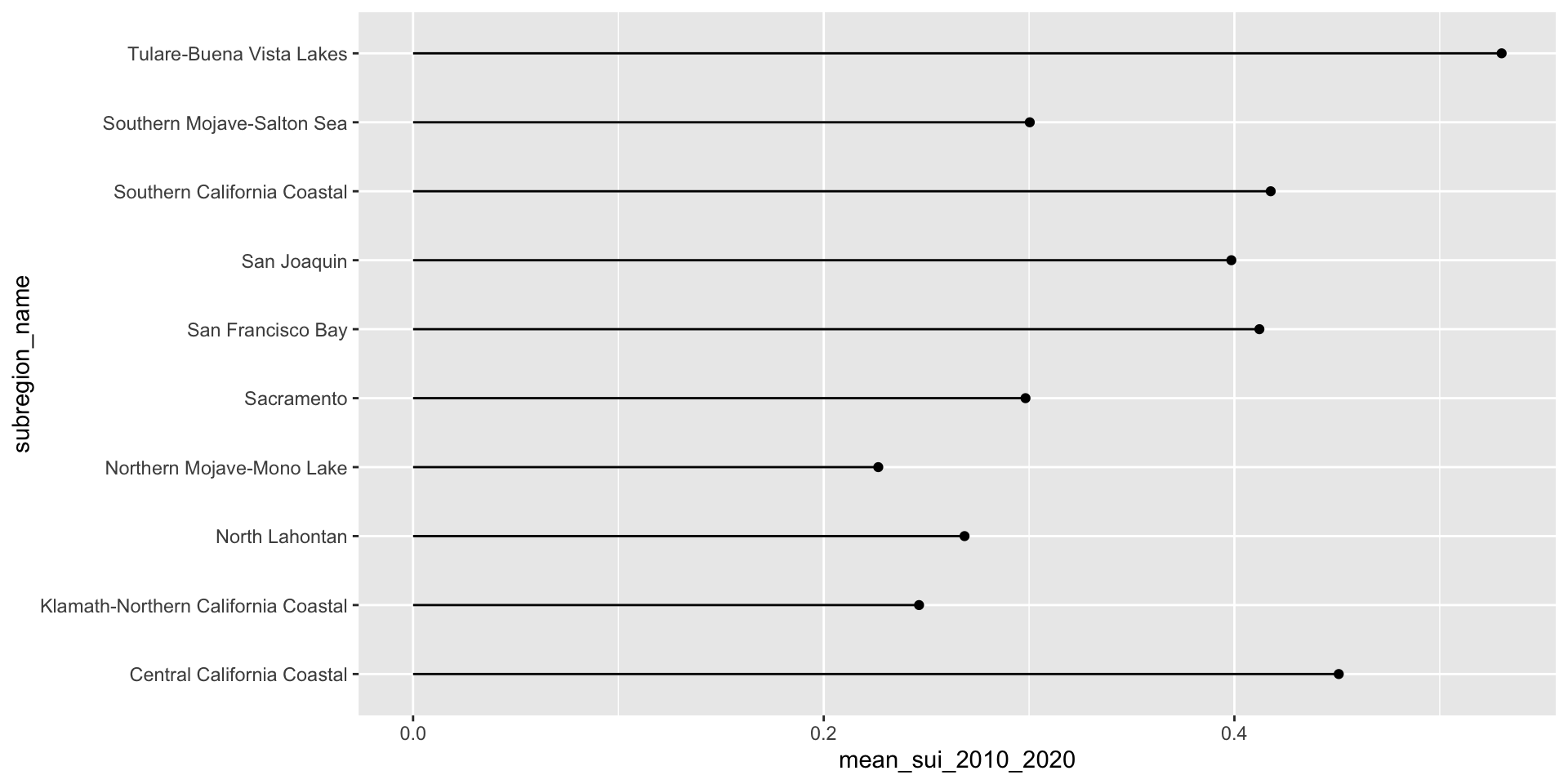
ggplot(aes(x = mean_sui_2010_2020, y = subregion_name)) +
geom_point() +
geom_linerange(aes(xmin = 0, xmax = mean_sui_2010_2020)) +
geom_text(aes(label = round(mean_sui_2010_2020, 2)), hjust = -0.3) +
scale_x_continuous(limits = c(0, 0.6))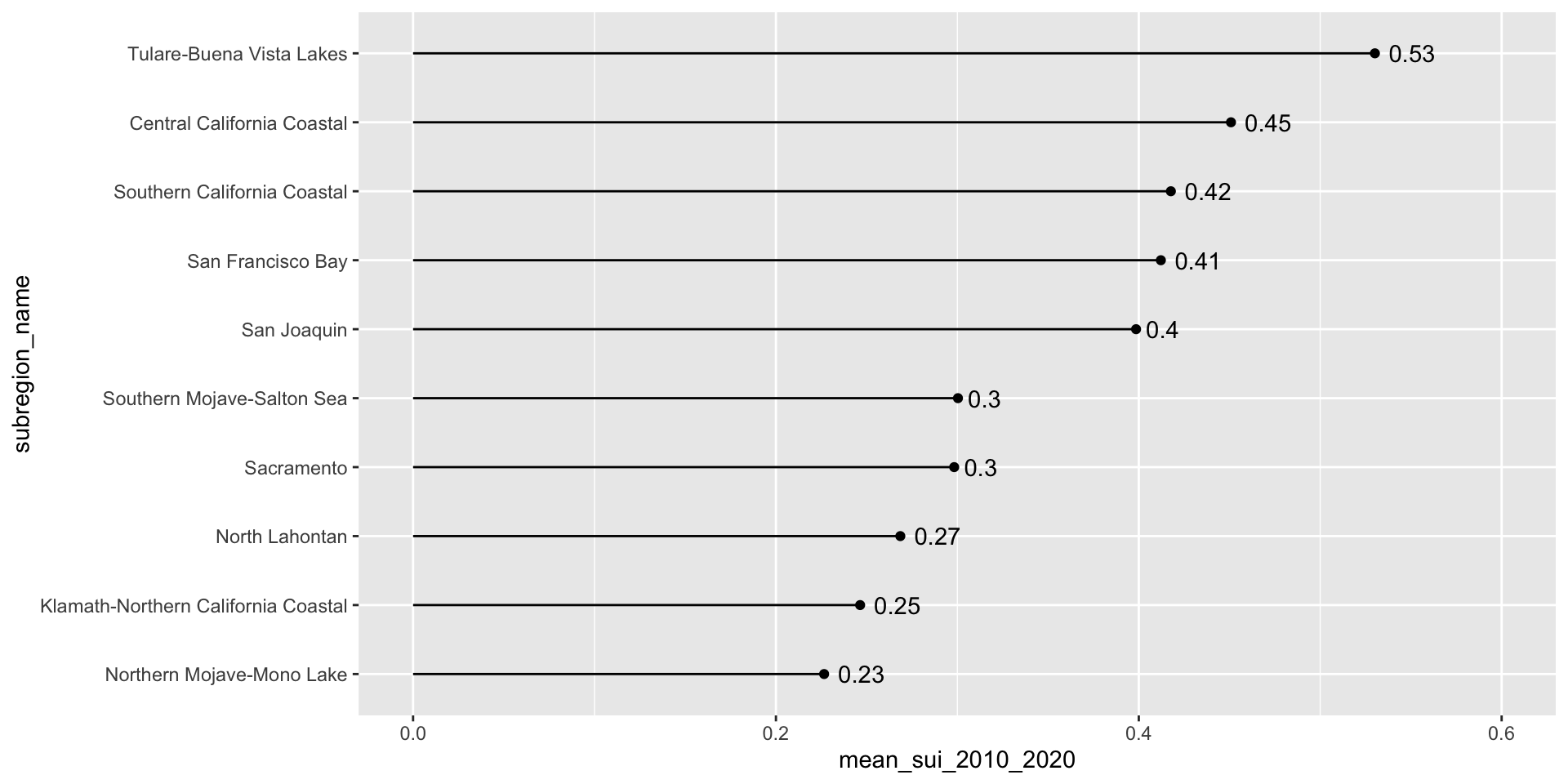
Use geom_col() when you want the heights of your bars to represent values in your data (i.e. you have a variable in your data set that maps to the length (or height) of your bars). Here, we already have a numeric variable in our data set called, mean_sui_2010_2020, which is mapped to the length of each bar in our plot:
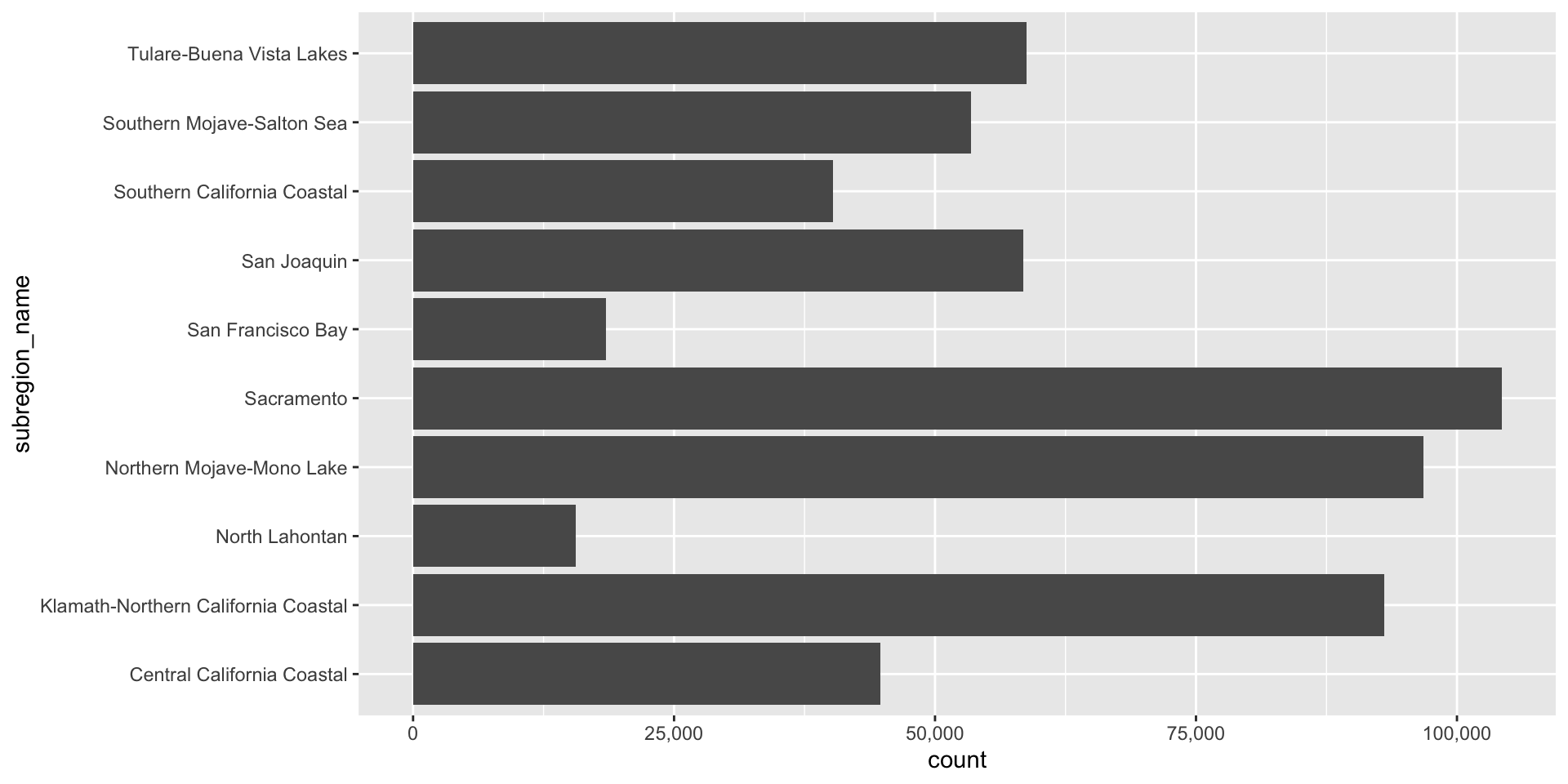
Use geom_bar() if you want the heights of your bars to be proportional to the number of cases in each group. E.g. if we want to know how many observations exist for each subregion (note that we don’t have a count column in our data frame – geom_bar() groups by subregion_name then counts the number of observations for each subregion_name group):
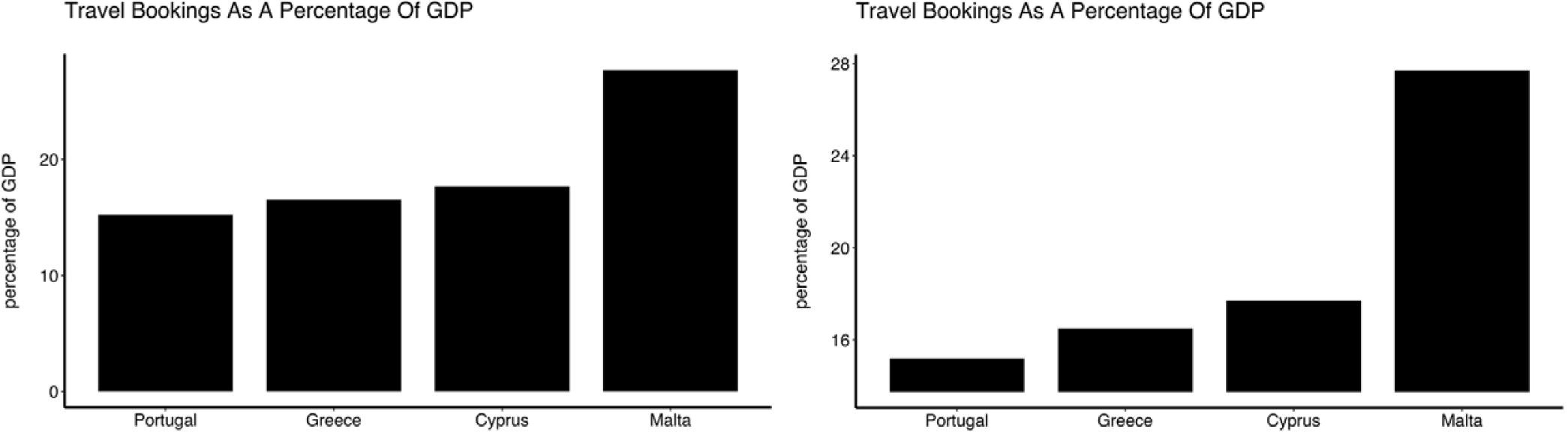
Because bar (and related) charts encode values by length from zero, cutting the axis exaggerates differences and is misleading. The axis must start at zero.
Truncated axes leads viewers to perceive illustrated differences as larger or more important than they actually are (i.e. a truncation effect). Yang et al. (2021) empirically tested this effect and found that this truncation effect persisted even after viewers were taught about the effects of y-axis truncation.
Figure 2 from Yang et al. 2021. The left-most plot without a truncated y-axis was presented to the control group of viewers. The right-most plot with a truncated y-axis was presented to the test group of viewers.
Because dot plots encode values by position, truncating the axis doesn’t distort comparisons. The axis does not have to start at zero.
When bars are all long and have nearly the same length, the eye is drawn to the middle of the bars rather than to their end points. A lollipop plot is a bit less distracting (less ink), but still difficult to differentiate risk scores across counties. When we limit the axis range in a dot plot, it becomes easier to identify differences in the max and min values.
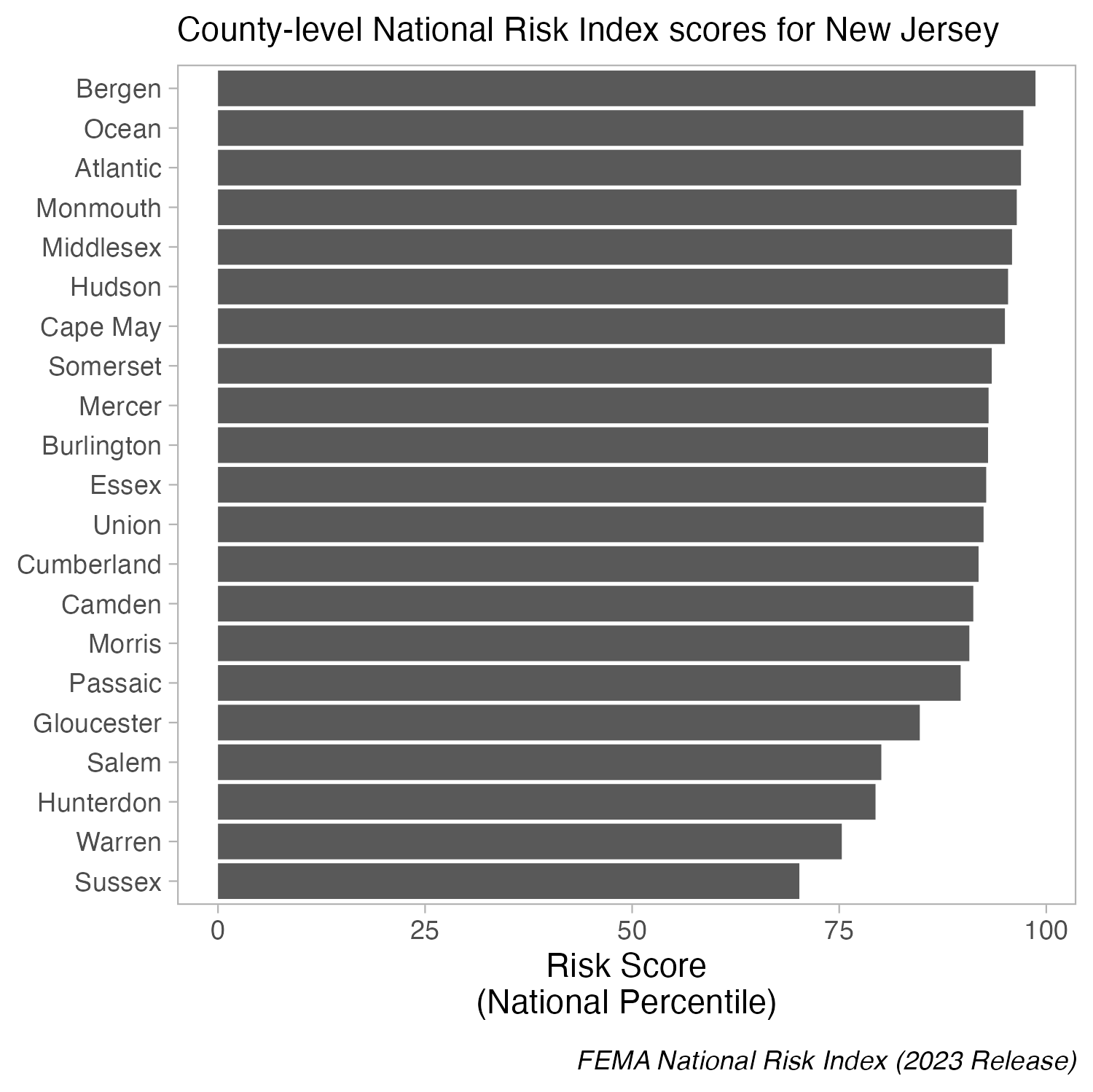
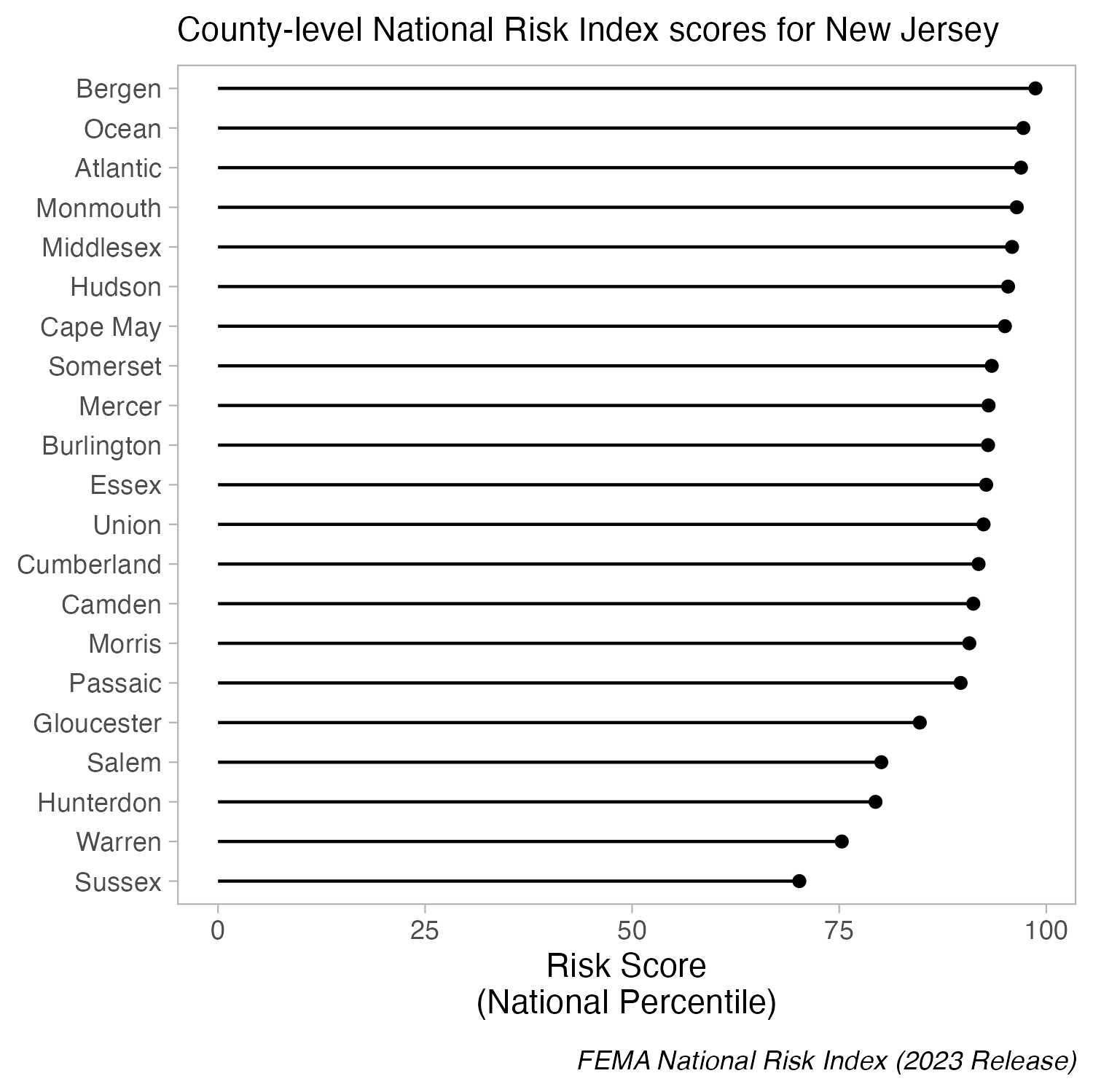
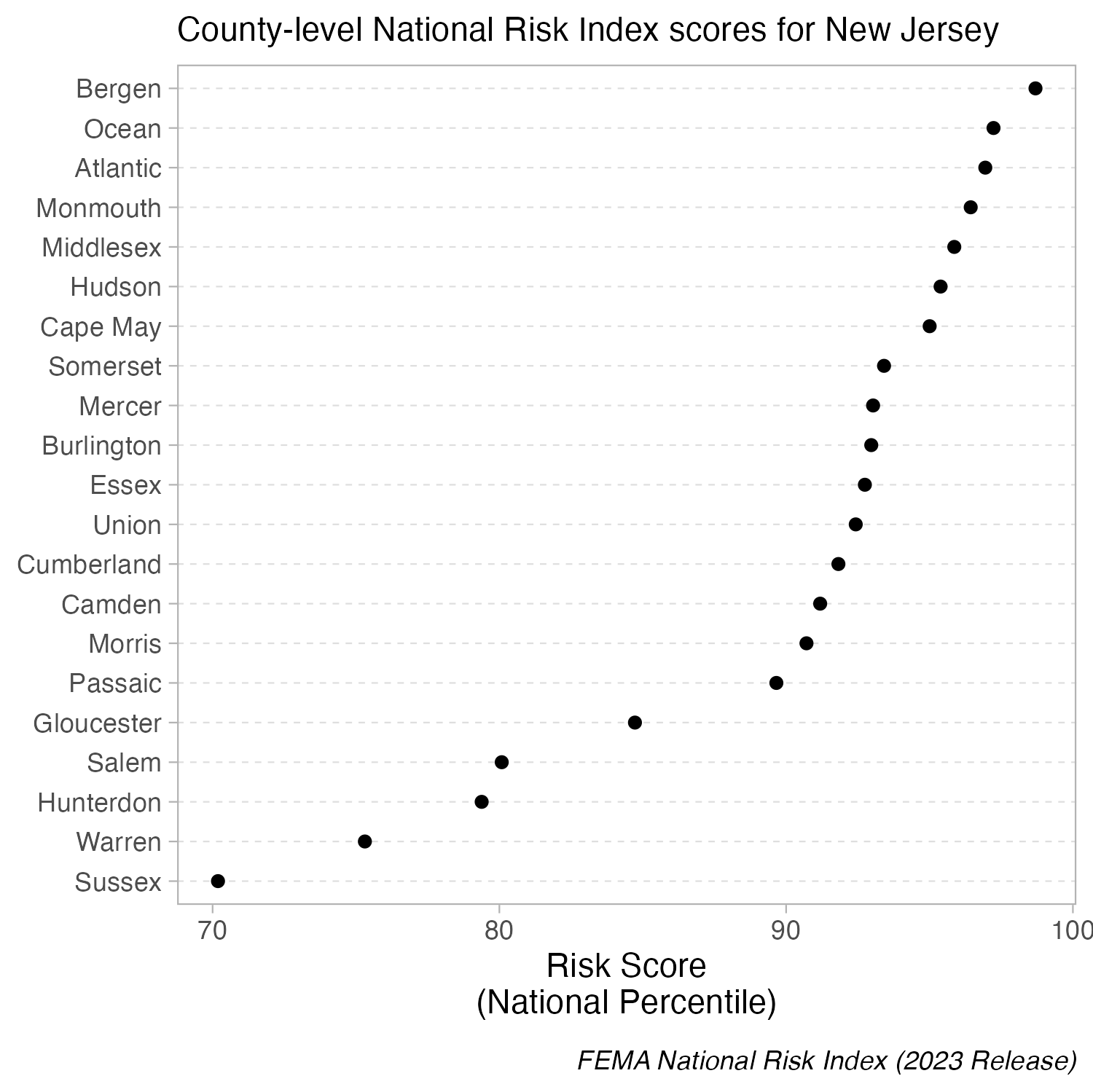
Bar plots shine when you need to compare counts (e.g. populations size of different countries). However, you should proceed with caution when using bar plots to visualize the distribution of / summarize your data. Doing so can be misleading, particularly when you have small sample sizes. Why?
bar plots hide the distribution of the underlying data (many different distributions can lead to the same plot)
when used this way, the height of the bar (typically) represents the mean of the data, which can cause readers to incorrectly infer that the data are normally distributed with no outliers (this of course may be true in some cases, but certainly not always)

The USGS classifies SUI into five categories: Very low (0.0 to <0.2), Low (0.2 to <0.4), Moderate (0.4 to <0.6), High (0.6 to <0.8), and Severe (0.8 to 1). Let’s say we want to look at how California subwatersheds (HUC12s) are distributed across these categories by month from 2010–2020. We can use a stacked bar plot, each bar represents a month and segments represent the number of subwatersheds in each SUI category. Let’s first do a bit of wrangling:
sui_severity <- ca_region |>
mutate(
sui_category = case_when(
sui_frac < 0.2 ~ "Very low",
sui_frac >= 0.2 & sui_frac < 0.4 ~ "Low",
sui_frac >= 0.4 & sui_frac < 0.6 ~ "Moderate",
sui_frac >= 0.6 & sui_frac < 0.8 ~ "High",
sui_frac >= 0.8 & sui_frac <= 1 ~ "Severe",
TRUE ~ NA
)) |>
group_by(month, sui_category) |>
summarize(tot_num_sui = n()) |>
drop_na(sui_category) |>
mutate(month = month.abb[month],
month = factor(month, levels = c(month.abb[10:12], month.abb[1:9]))) # order months Oct > Sep (water year)03:00
The code for a stacked bar plot is not so different from a standard bar plot – just add a categorical variable as your fill:
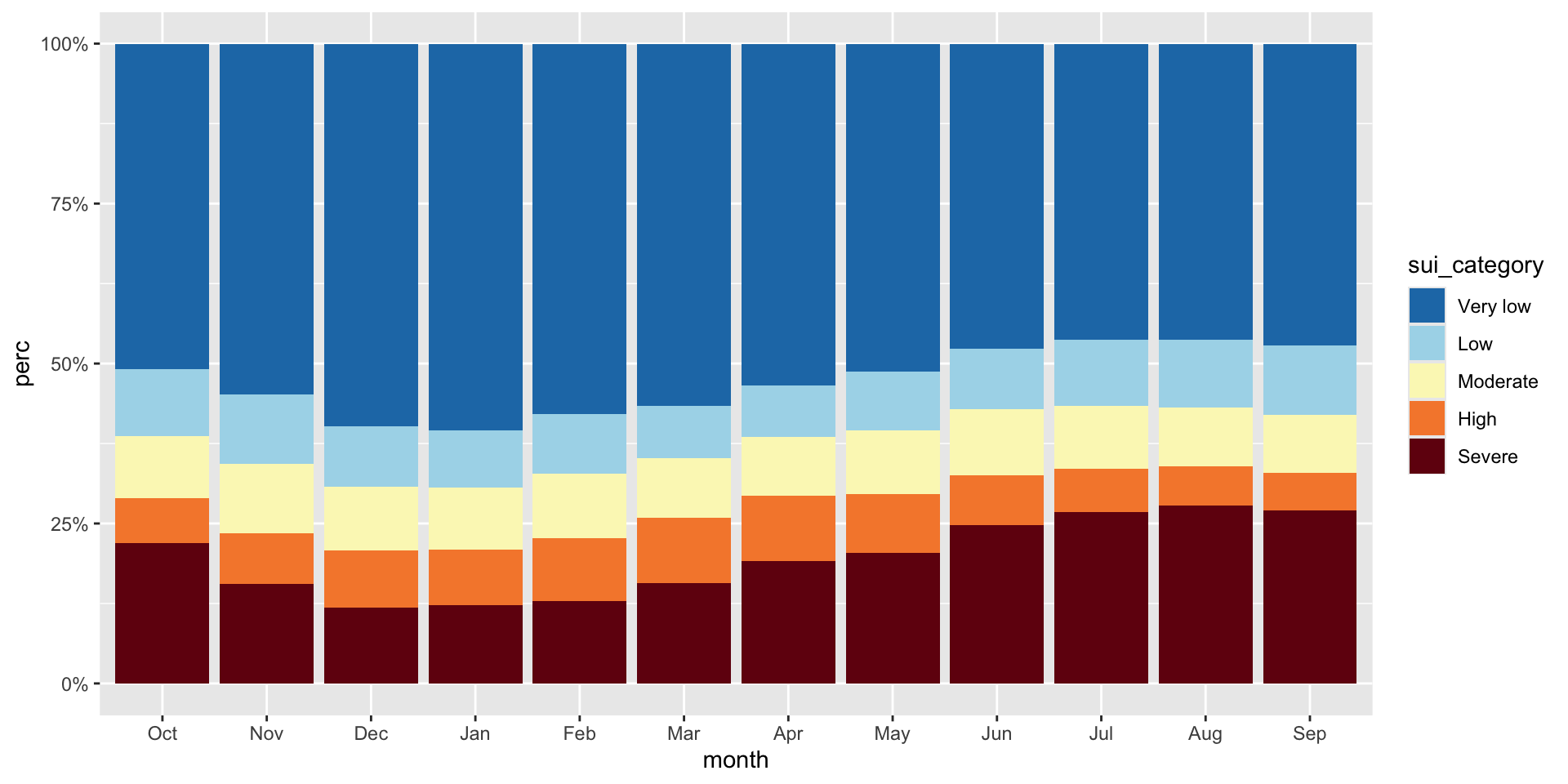
To make interpretation easier, we should (1) reorder sui_category so that they’re in a logical order and that the most important (Severe) is on the bottom (making it easier to read against the y-axis; we should update our legend order to reflect this as well), (2) convert our y-axis values to percentages, and (3) update our colors (we can adopt those used by USGS – see this slide)
#......................create color palette......................
# pulled hex codes from USGS map using ColorZilla Chrome extension
sui_colors <- c("Severe" = "#720C0F",
"High" = "#F68939",
"Moderate" = "#FBF7BF",
"Low" = "#AAD9EA",
"Very low" = "#217AB5")
#...................create % stacked bar chart...................
ggplot(sui_severity, aes(x = month, y = tot_num_sui, fill = sui_category)) +
geom_col(position = "fill") +
scale_fill_manual(values = sui_colors) +
scale_y_continuous(labels = scales::label_percent(scale = 100))
Now let’s look at how water stress changes through time for each of the ten HUC 18 subregions. We can use a heatmap to create a matrix that displays annual mean SUI values (numeric, continuous), calculated by averaging monthly observations within each year, by subregion (categorical) and year (categorical). We need to do a bit of wrangling:
Image source: Data Viz Project.
#...........df of annual mean SUI by subregion & year ...........
heatmap_data <- ca_region |>
group_by(subregion_name, year) |>
summarize(annual_mean_sui = mean(sui_frac, na.rm = TRUE)) |>
ungroup()
#.determine order of subregions based on highest avg SUI in 2015.
# it's likely that you'll first try making a plot with `heatmap_data`, then return to wrangle the order once you decide how best to arrange your groups
order_2015 <- heatmap_data |>
filter(year == 2015) |>
arrange(annual_mean_sui) |>
mutate(order = row_number()) |>
select(subregion_name, order)
#........join order with rest of data to set factor levels.......
heatmap_order <- heatmap_data |>
left_join(order_2015) |>
mutate(subregion_name = fct_reorder(.f = subregion_name, .x = order))
How you order your groups can (1) make it easier for readers to extract patterns and comparisons, and (2) shape the story the visualization tells. Here, subregions are ordered based on their average annual SUI in 2015, the end of a particularly dry stretch of years. How else might you consider ordering these groups?
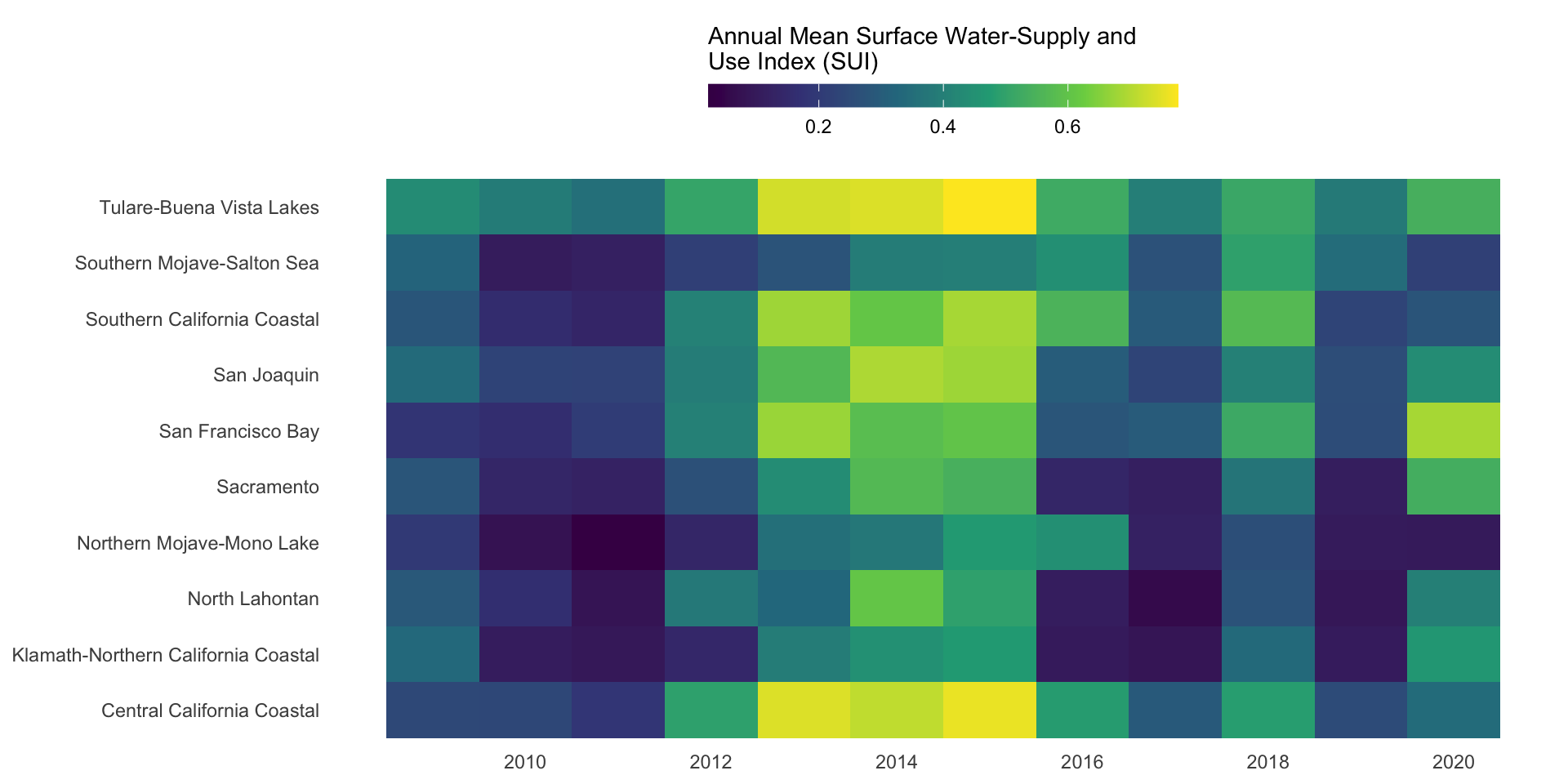
ggplot(heatmap_order, aes(x = year, y = subregion_name, fill = annual_mean_sui)) +
geom_tile() +
labs(fill = "Annual Mean Surface Water-Supply and\nUse Index (SUI)") + # caption = "A higher index value indicates greater water stress."
scale_fill_viridis_c() +
scale_x_continuous(breaks = seq(2010, 2020, by = 2)) +
guides(fill = guide_colorbar(barwidth = 15, barheight = 0.75, title.position = "top")) +
theme_minimal() +
theme(
legend.position = "top",
axis.title = element_blank(),
panel.grid = element_blank()
)
Let’s say we want to compare mean monthly water availability and consumption in the Santa Barbara Coastal subbasin (HUC8: 18060013) across the years 2010-2020. We can use a dumbbell (aka Cleveland) plot to display the average amount of water (mm; numeric) available vs. consumed (categorical), by month (categorical).
Image source: Data Viz Project
Image source: County of Santa Barbara Public Works
Here, it makes sense to order the y-axis groups chronologically (Oct > Sep). If your grouping variable is not inherently chronological (e.g. if comparing water availability and consumption across different subbasins), a common approach is to order groups by a mean or max value. See this archived version of the lecture for an alternative dumbbell plot example where we order differently.
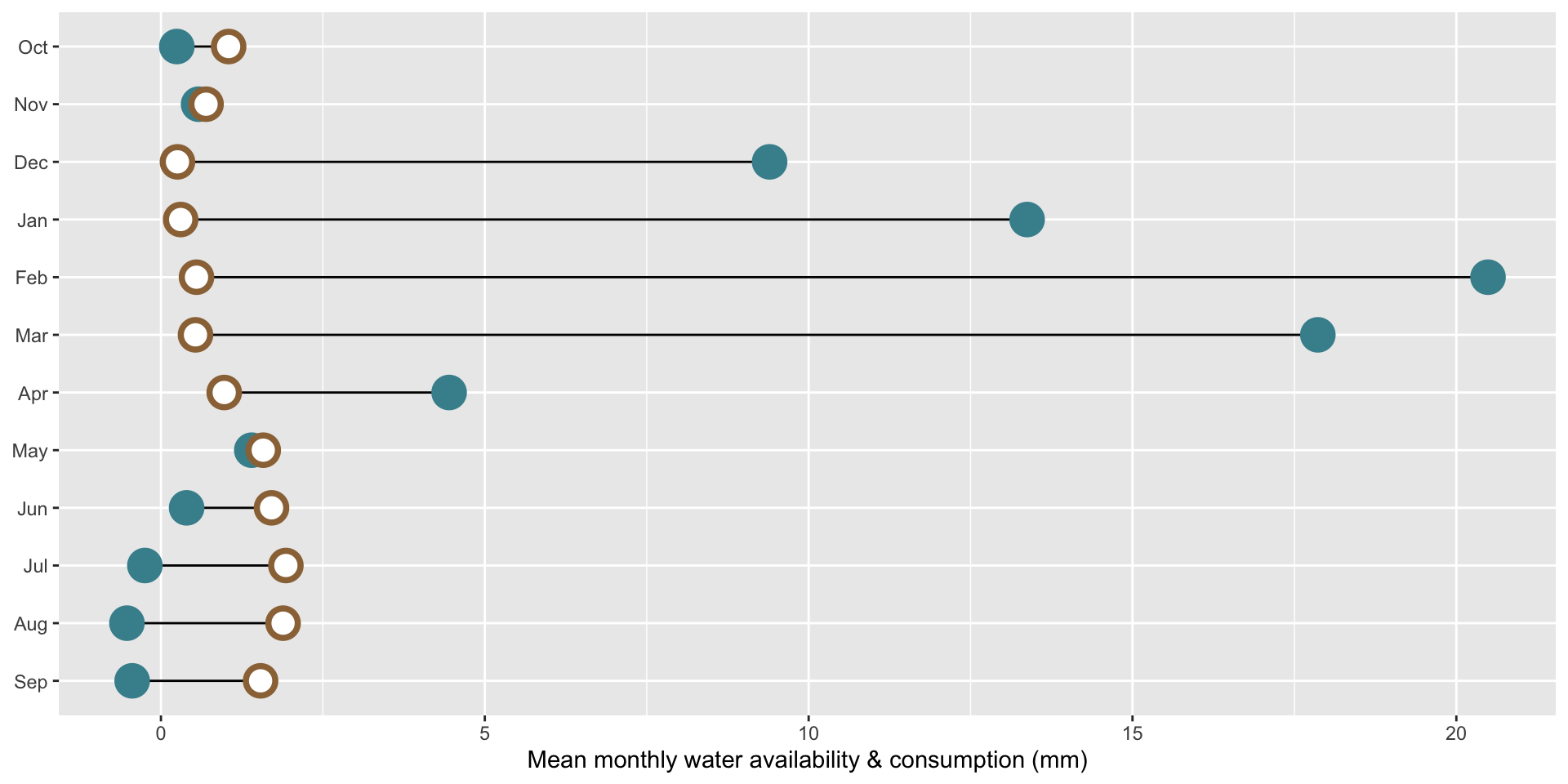
ggplot(sbc_subbasin_monthly) +
geom_linerange(aes(y = month,
xmin = mean_consum, xmax = mean_avail)) +
ggeom_point(aes(x = mean_avail, y = month),
color = "#448F9C",
size = 5,
stroke = 2) +
geom_point(aes(x = mean_consum, y = month),
color = "#9C7344",
fill = "white",
shape = 21,
size = 5,
stroke = 2) +
labs(x = "Mean monthly water availability & consumption (mm)") +
theme(axis.title.y = element_blank())