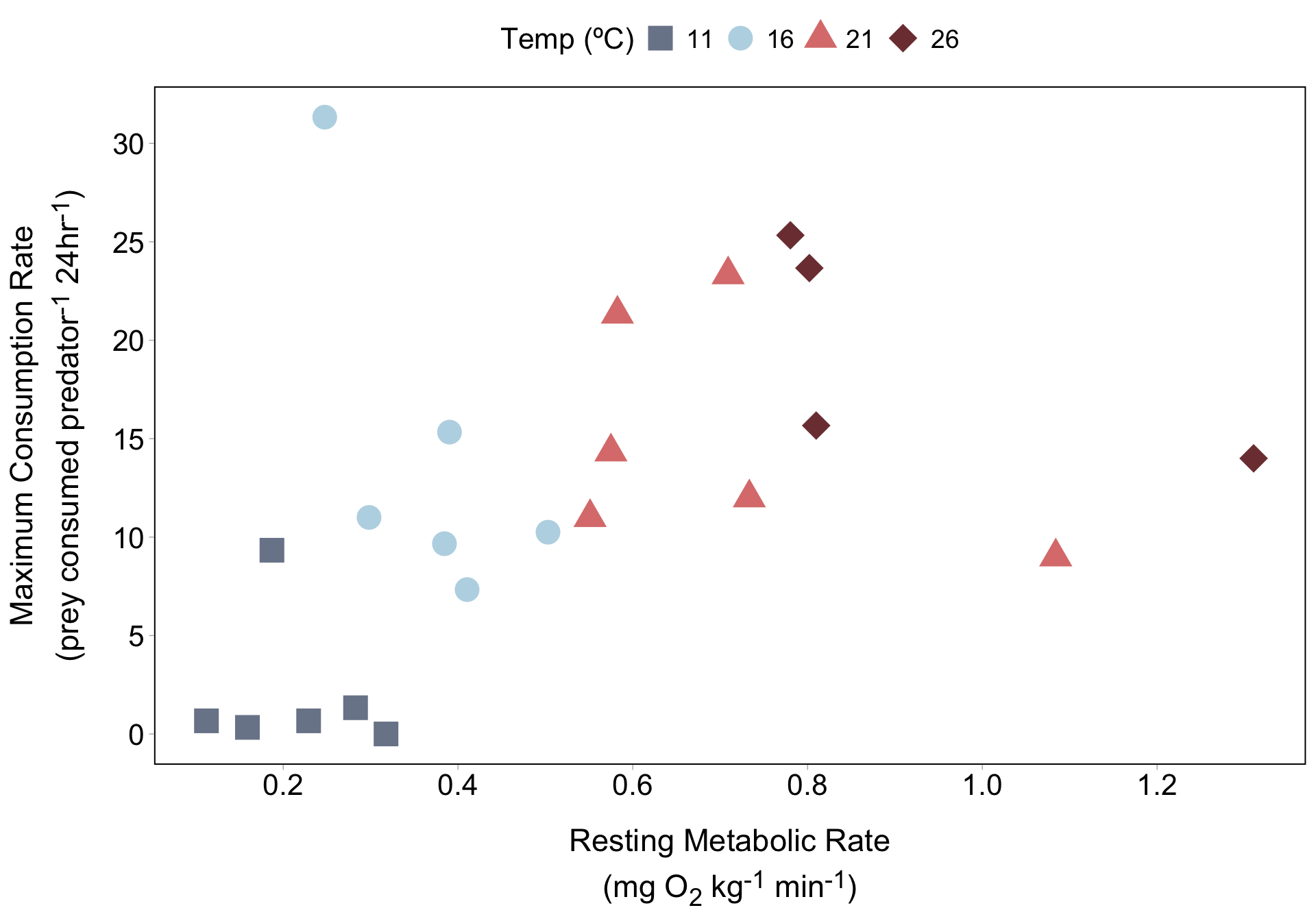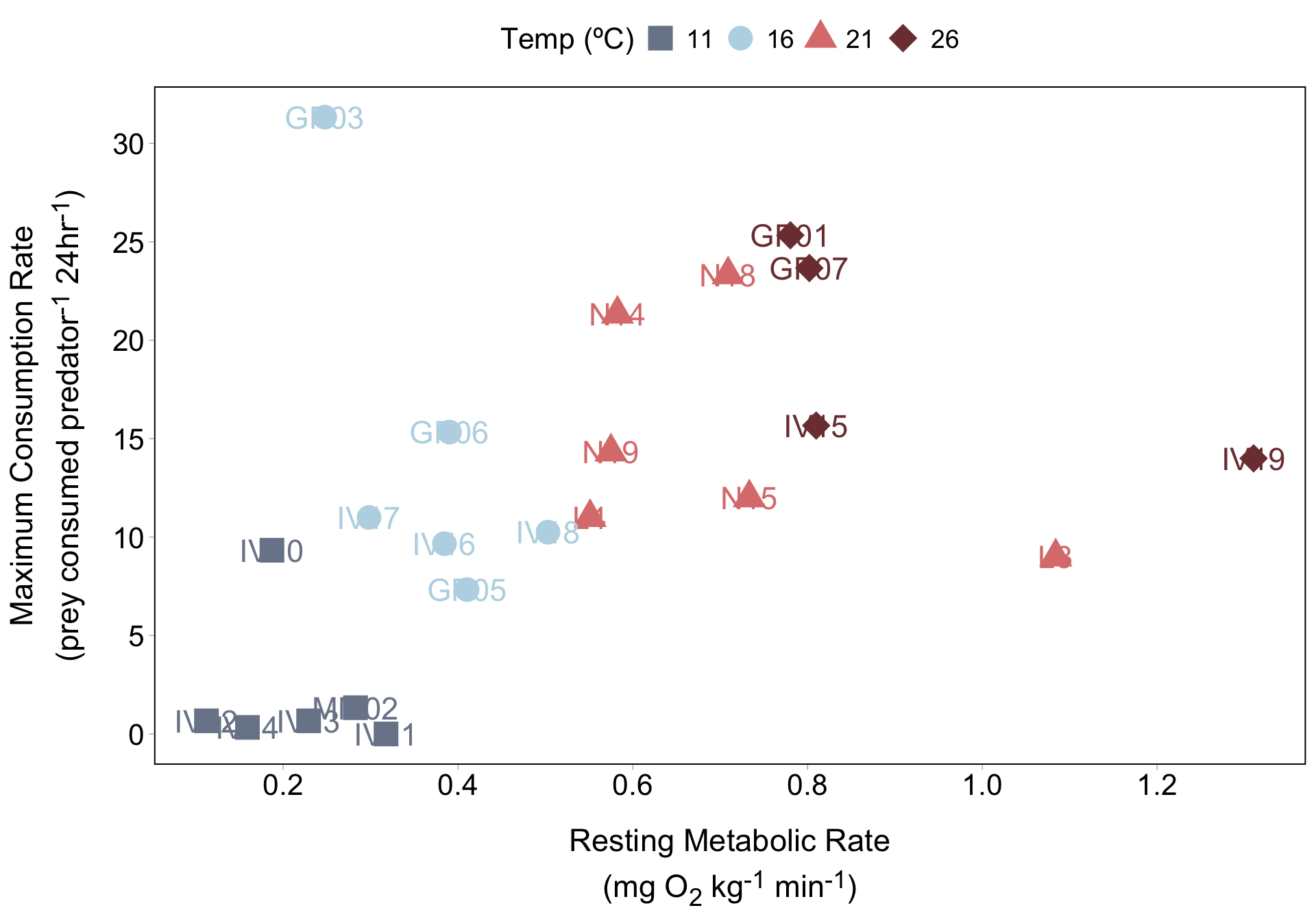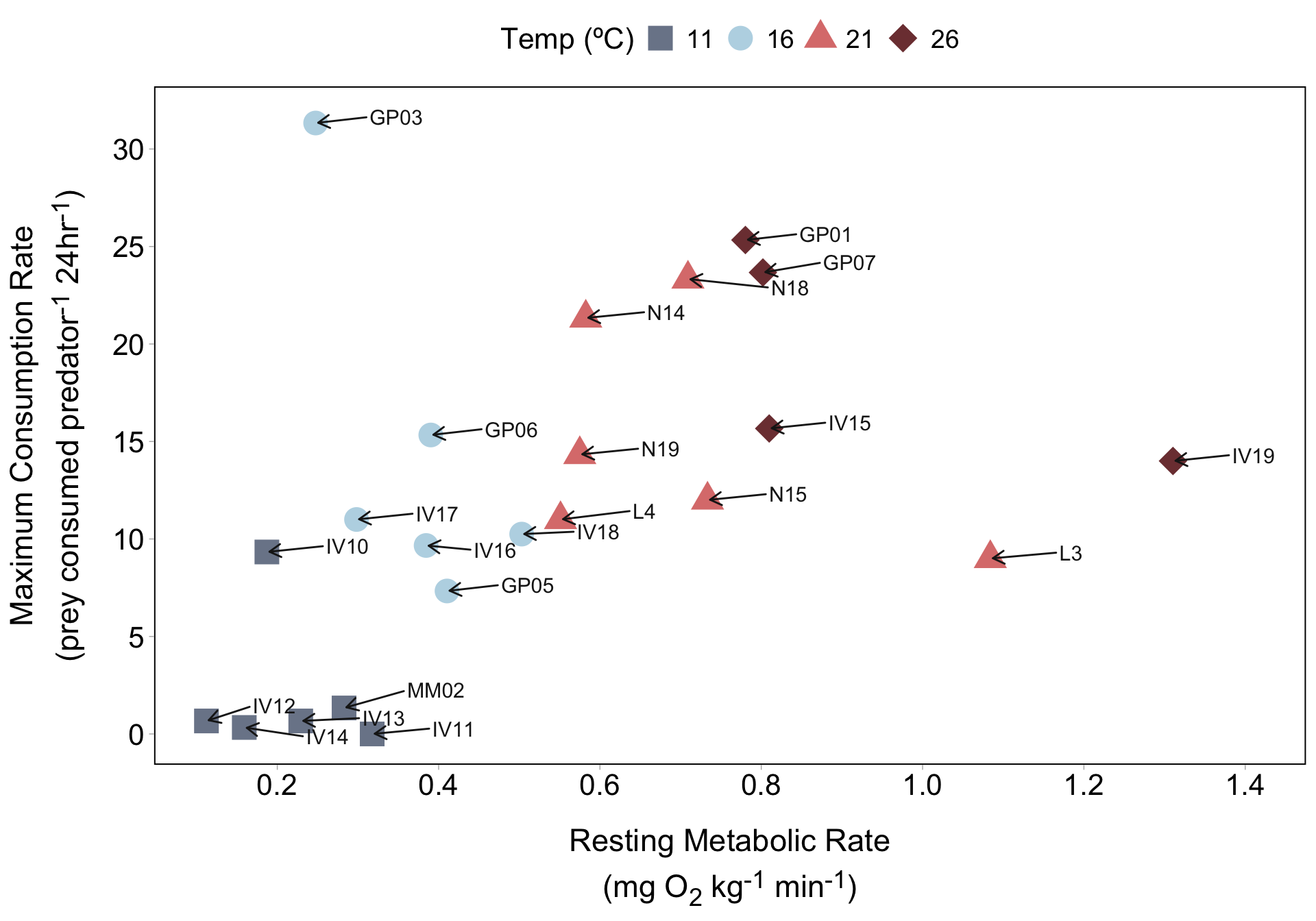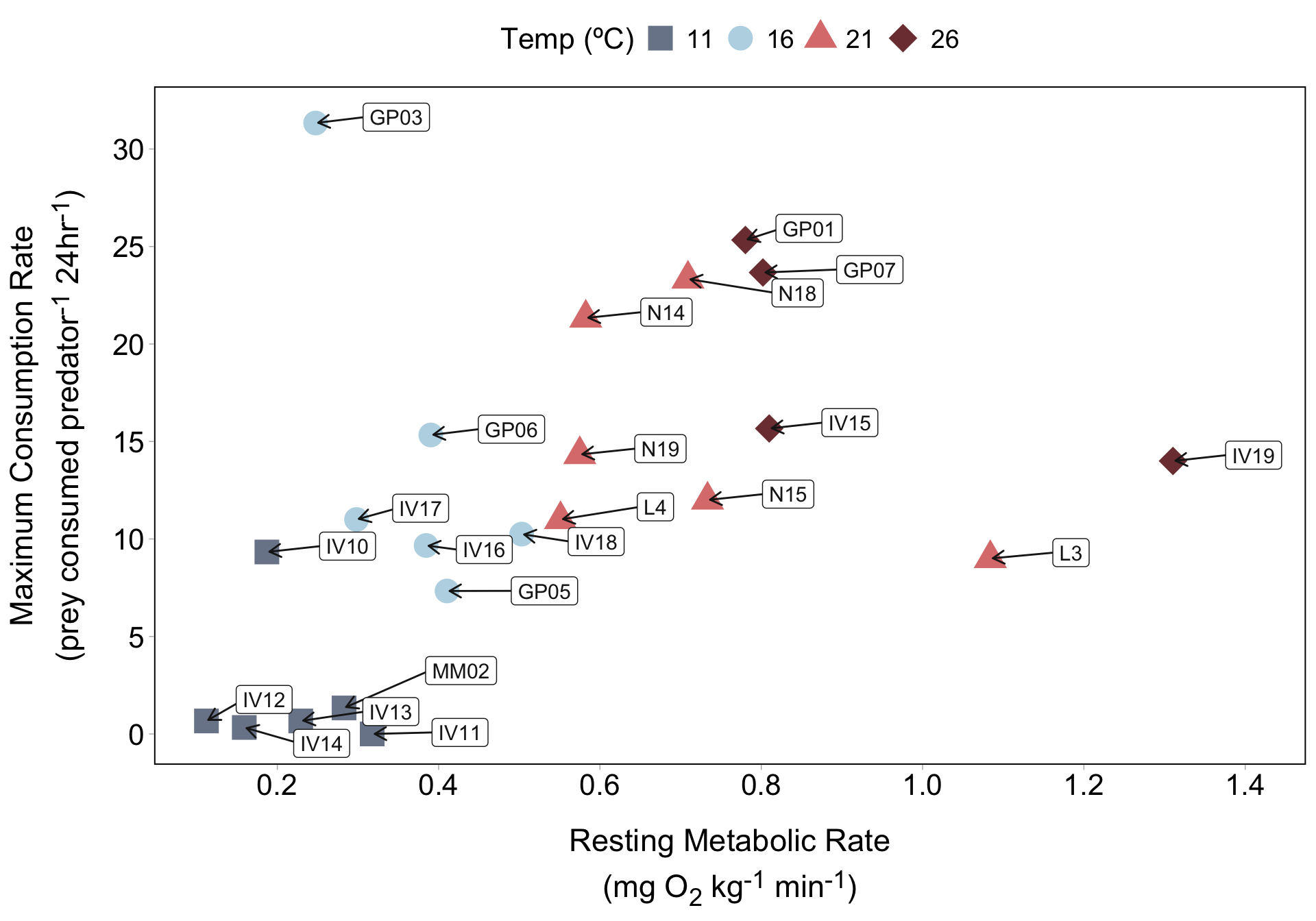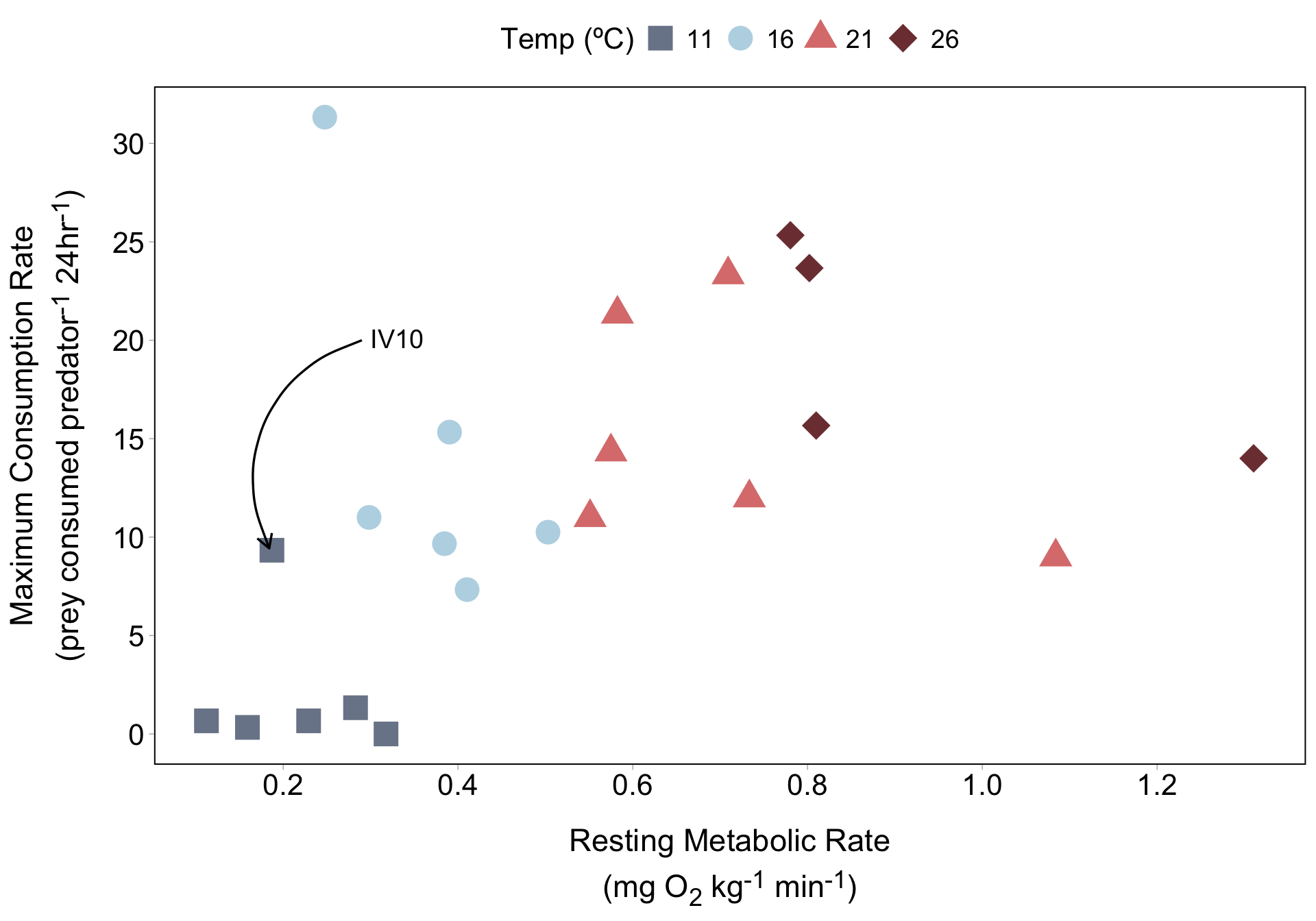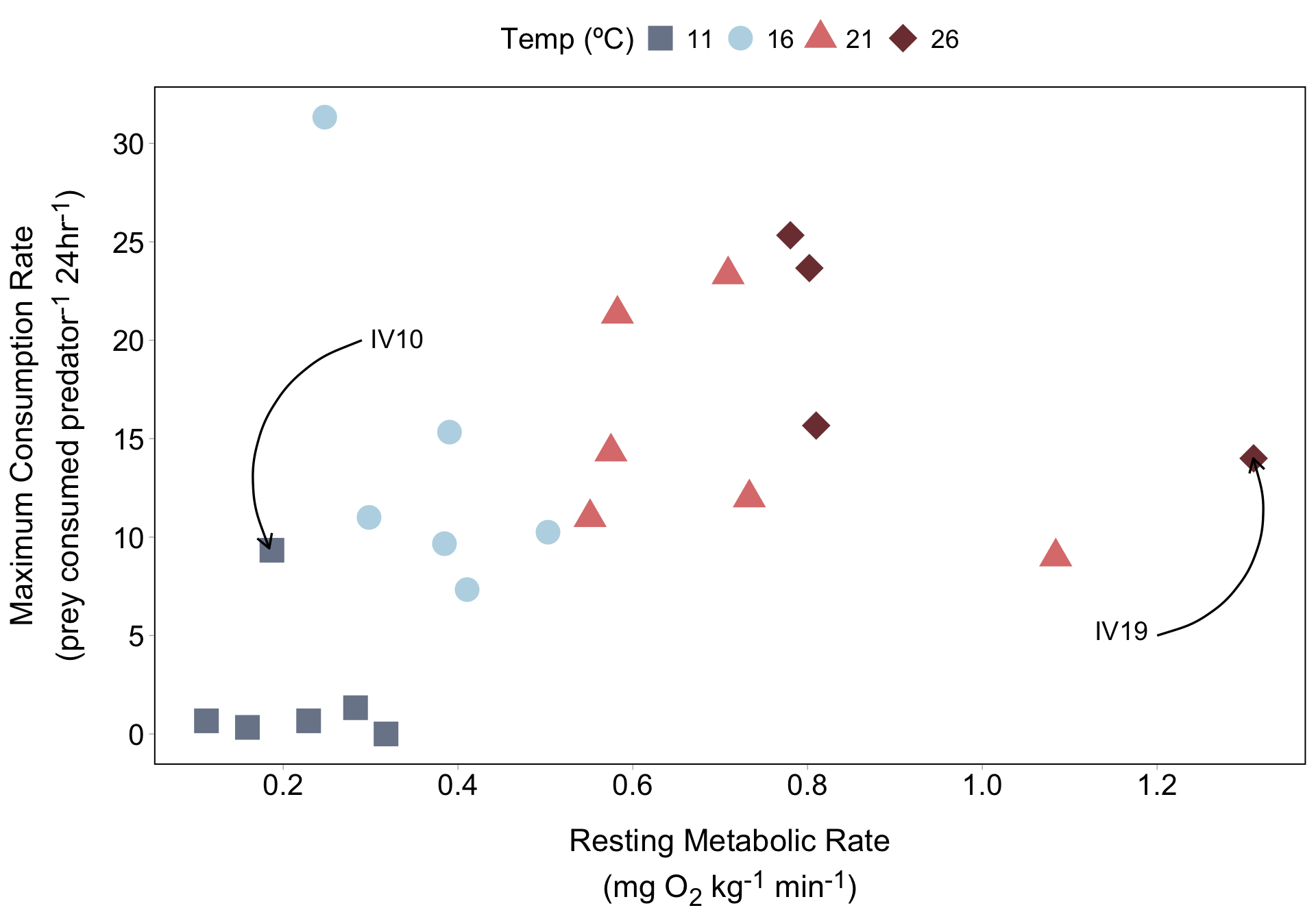
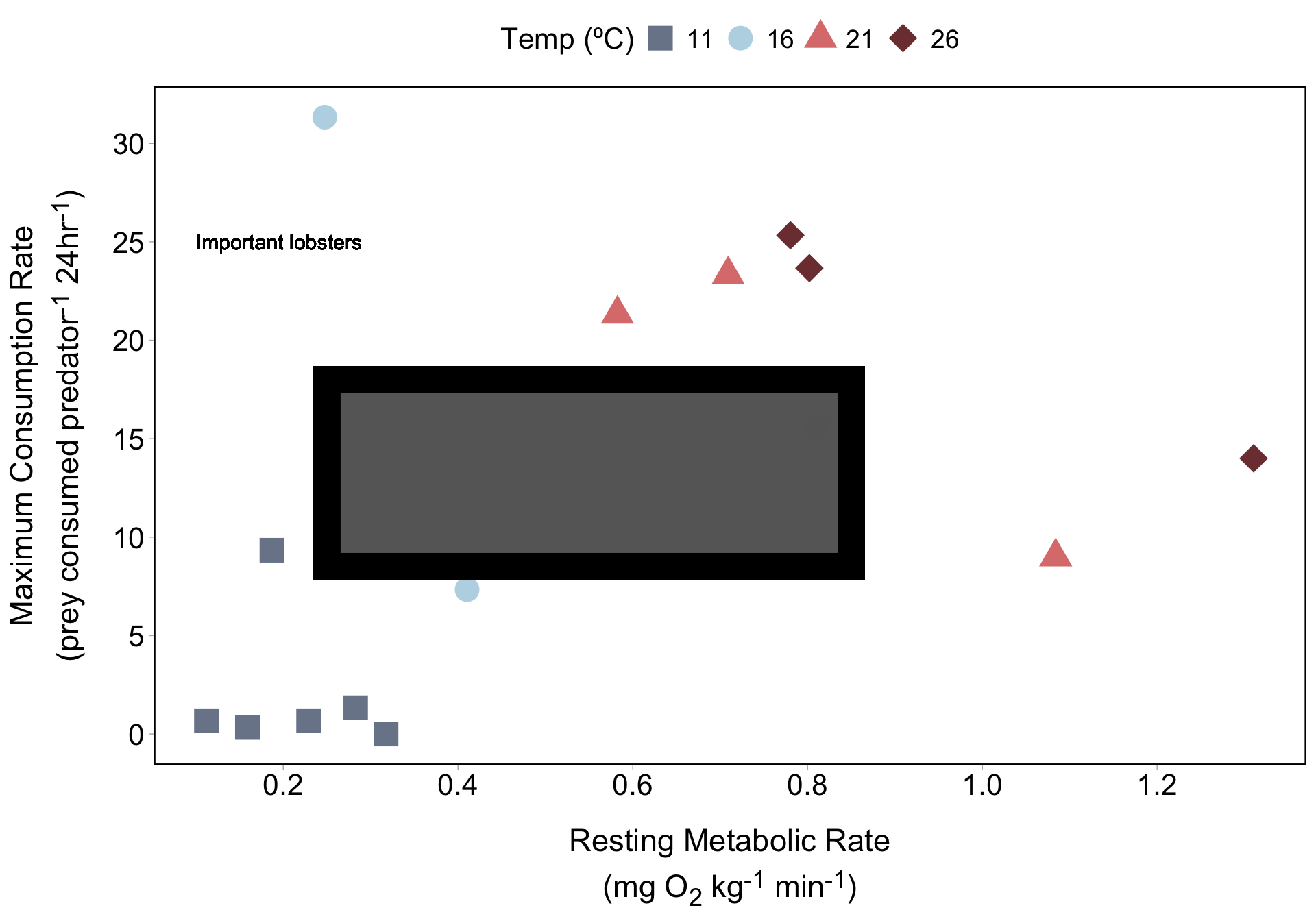
Metabolism effects on foraging across temperatures
02:00
02:00
02:00
02:00
02:00
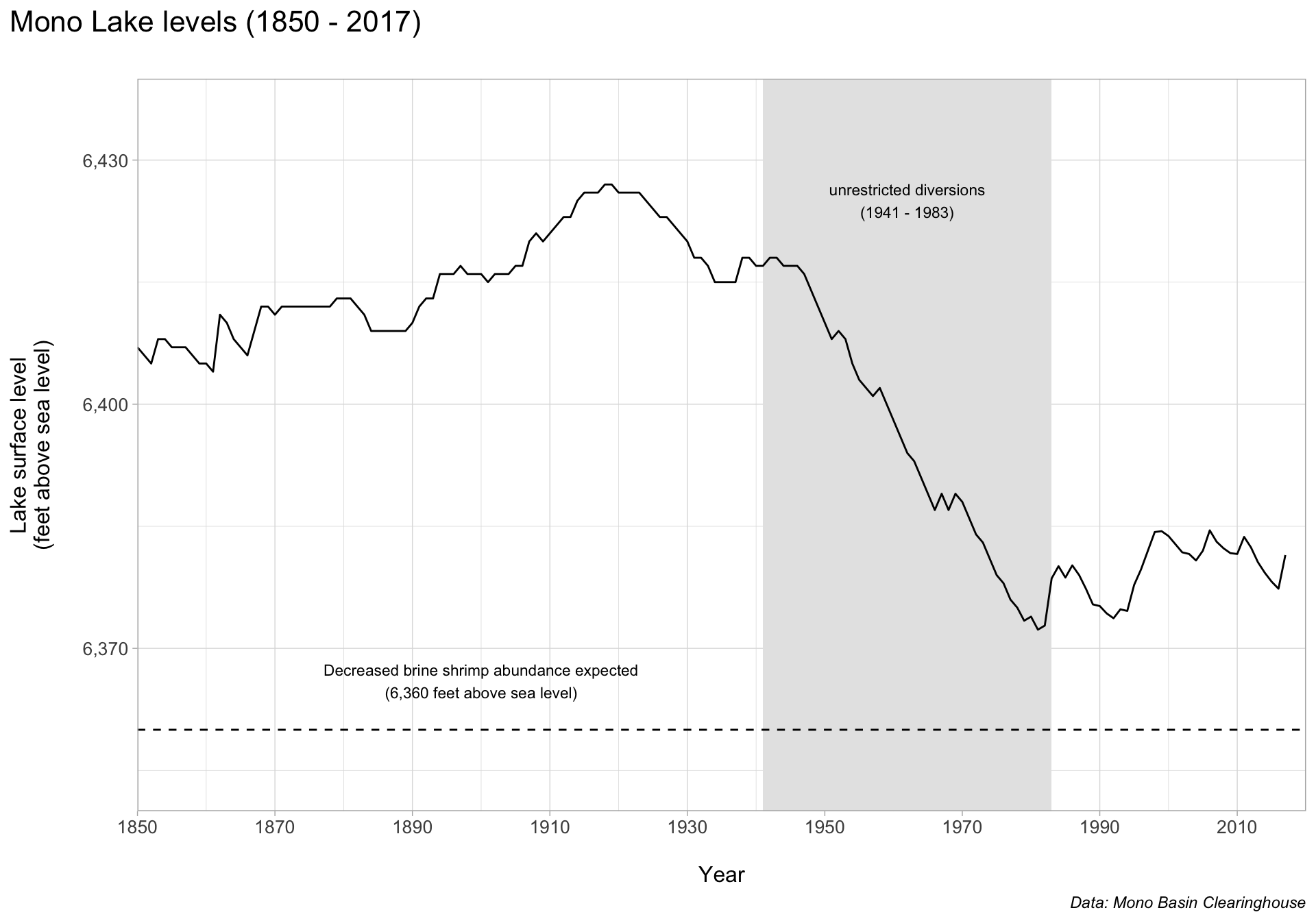
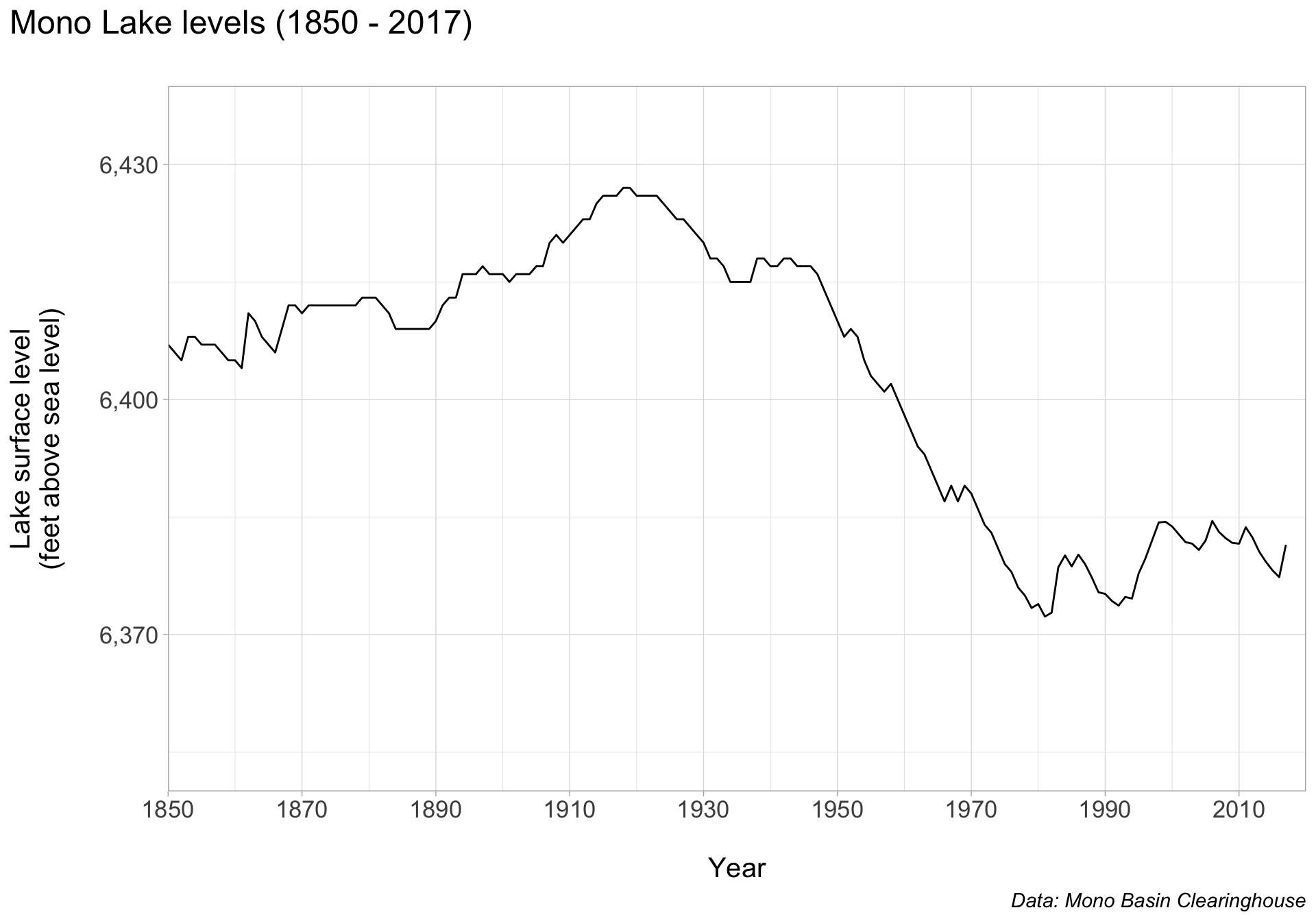
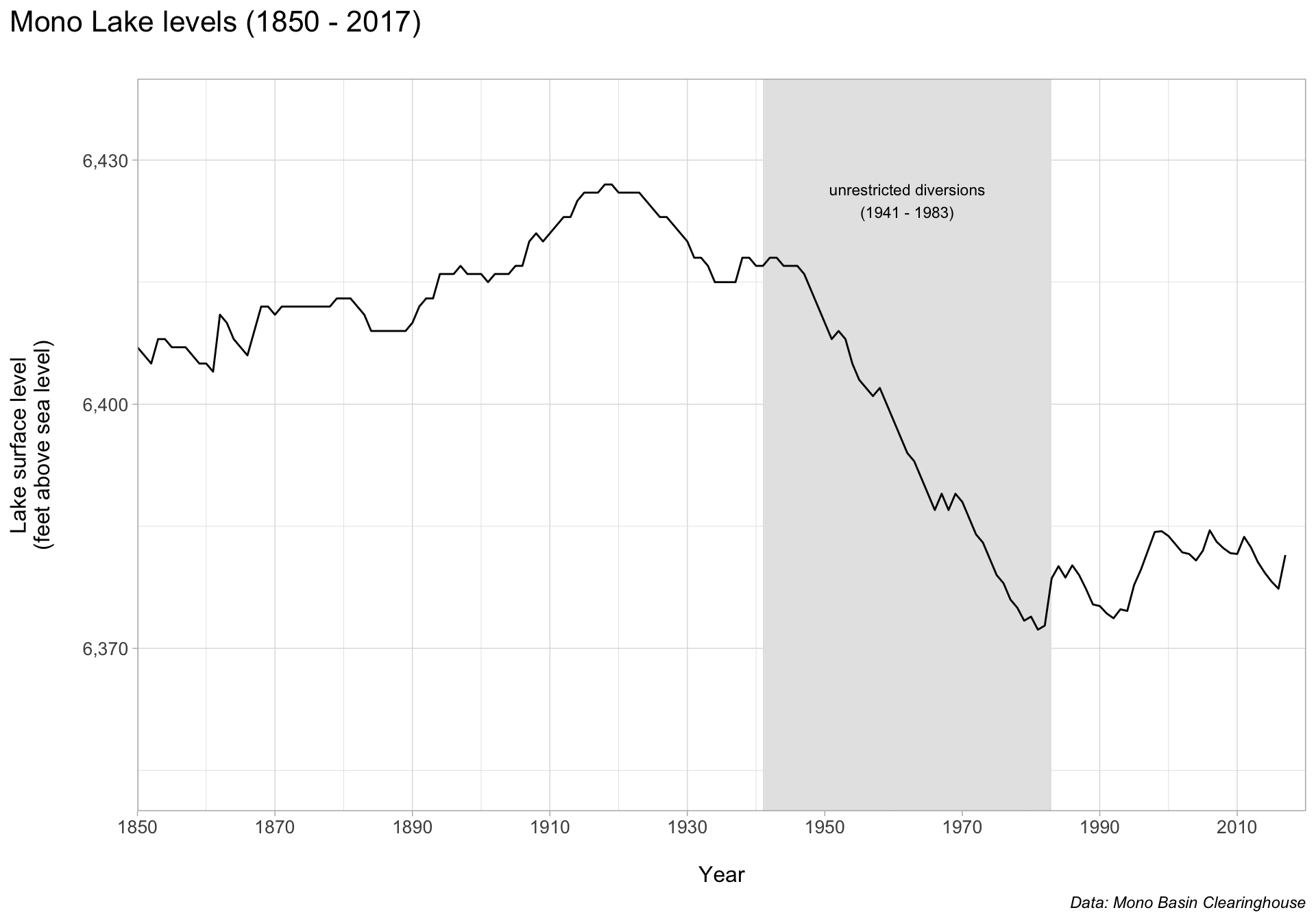
Mono Lake levels
Borrowed from Allison Horst’s Customized Data Visualization in {ggplot2} materials.
Here, we use geom_text() + geom_rect() to add text and a rectangle to our plot. We need to supply coordinates to place each on our plot.
Notice that our text looks oddly blurry and bold, and our rectangle is opaque (despite adjusting alpha) and has a weird, thick border.
Alternatively, annotate() requires that we define a geom type (e.g. "text", "rect"). We’ll also omit the show.lengend argument, since annotate() doesn’t produce a legend.
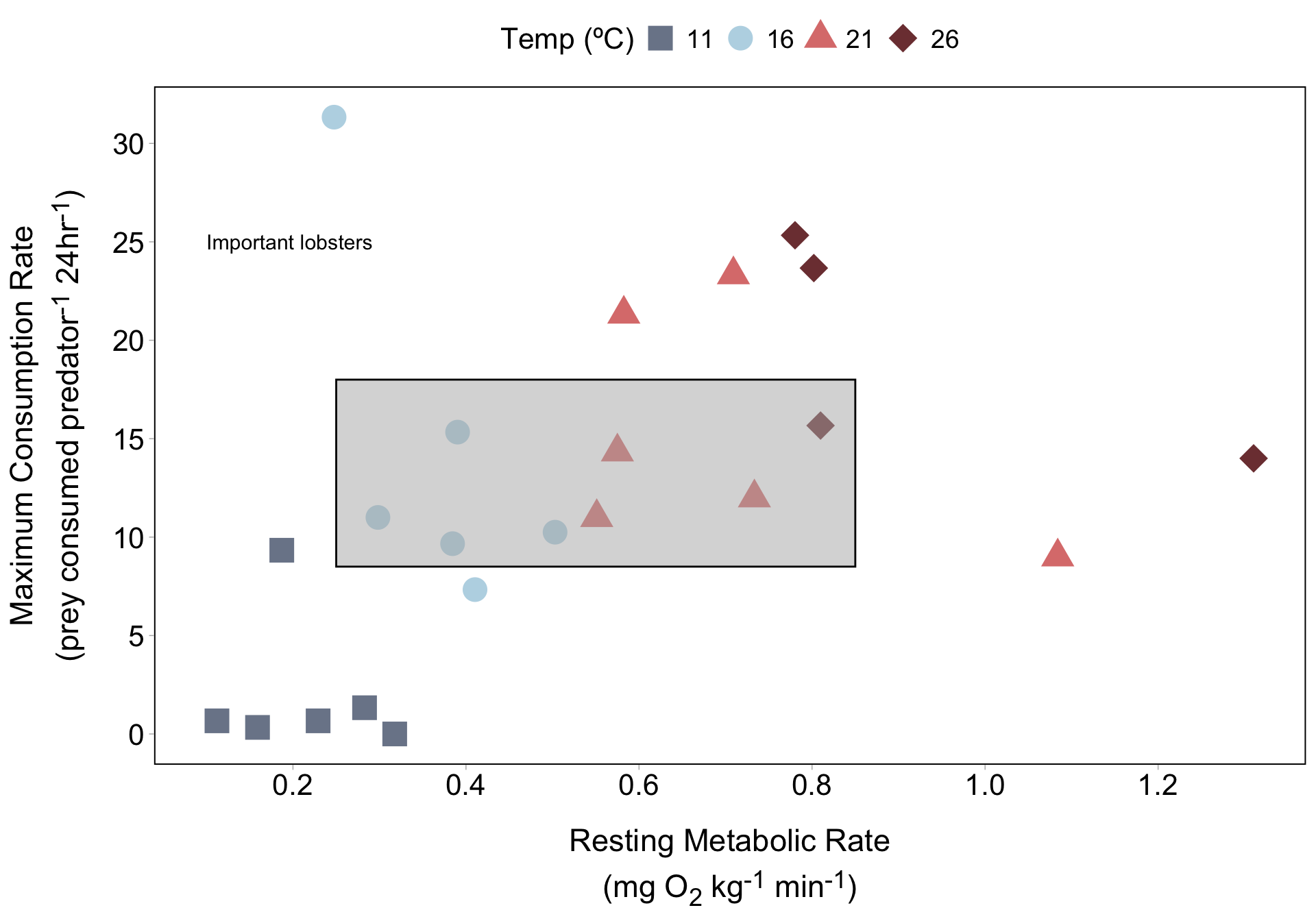
Note: Determining coordinates for any annotation requires a lot of trial and error. Pick values that you think are close and then tweak from there.
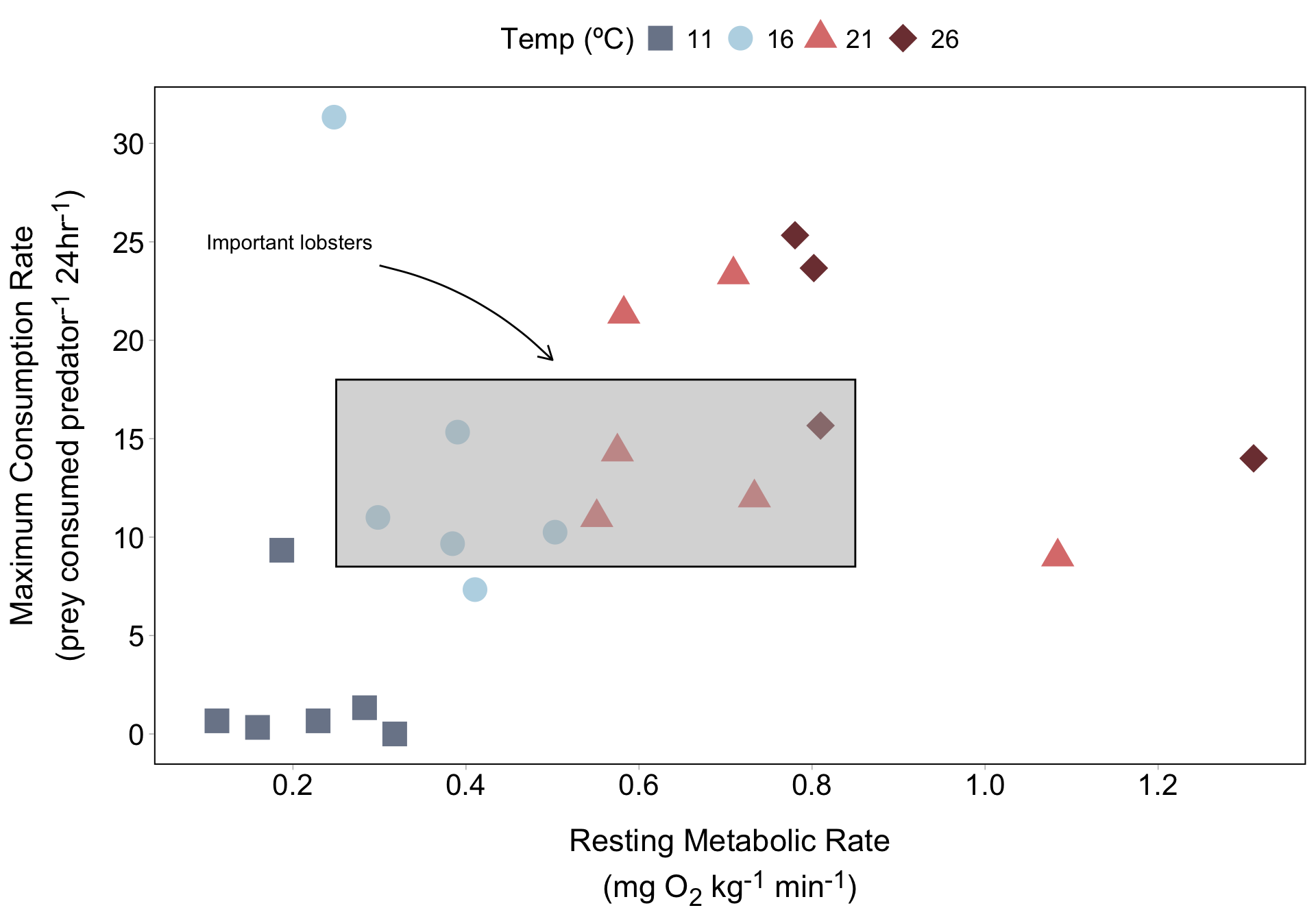
We can specify the "curve" geom type to draw a curved line. Use the arrow argument + arrow() function to add an arrow tip on the end:
lob_plot +
annotate(
geom = "text",
x = 0.1,
y = 25,
label = "Important lobsters",
size = 4,
color = "black",
hjust = "inward"
) +
annotate(
geom = "rect",
xmin = 0.25, xmax = 0.85,
ymin = 8.5, ymax = 18,
alpha = 0.5,
fill = "gray70", color = "black"
) +
annotate(
geom = "curve",
x = 0.3, xend = 0.5,
y = 23.8, yend = 19,
curvature = -0.15,
arrow = arrow(length = unit(0.3, "cm"))
)
geom_text() adds plain text
Annotations sit on top of data points, which may be undesirable…
geom_text() adds plain text
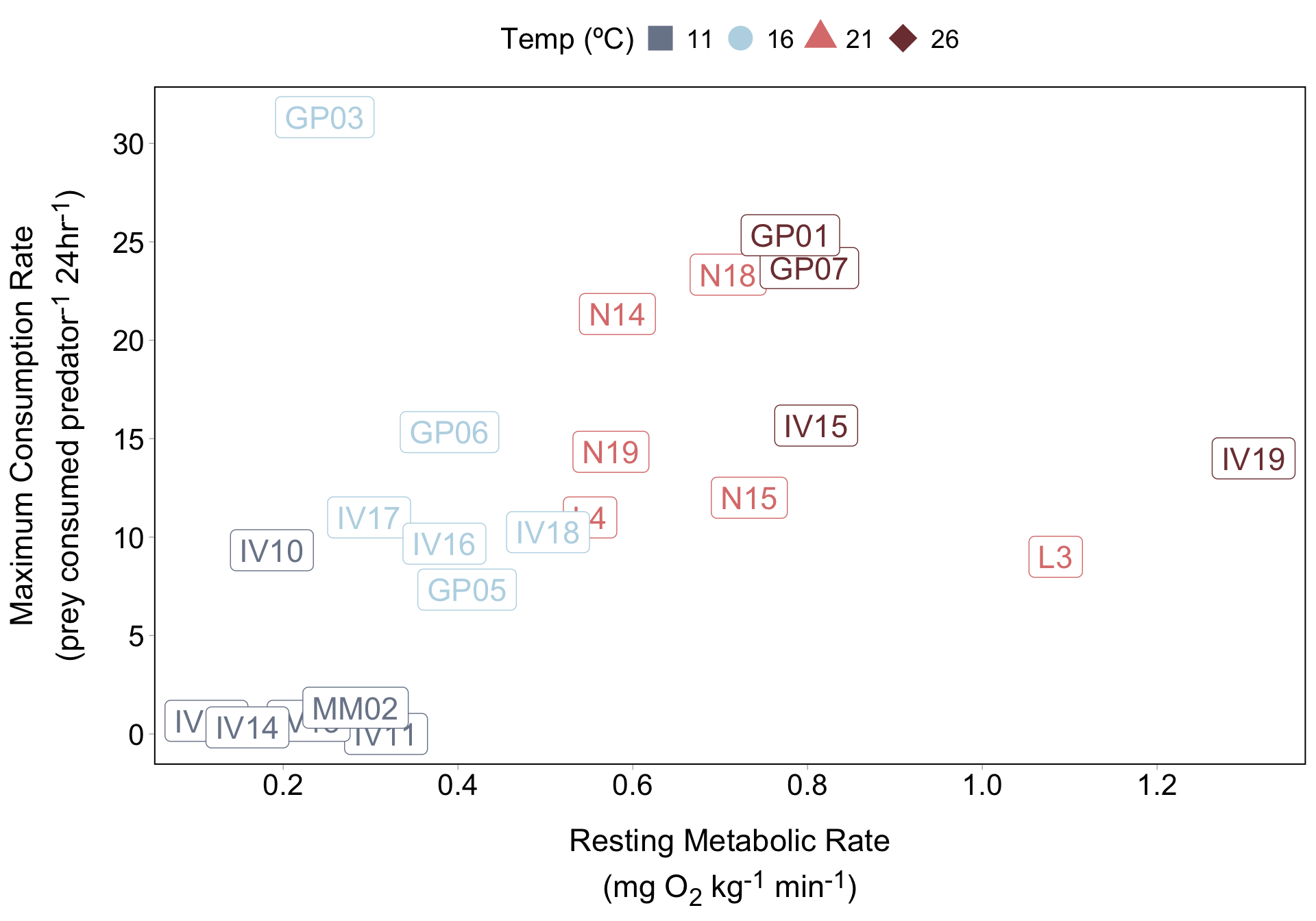
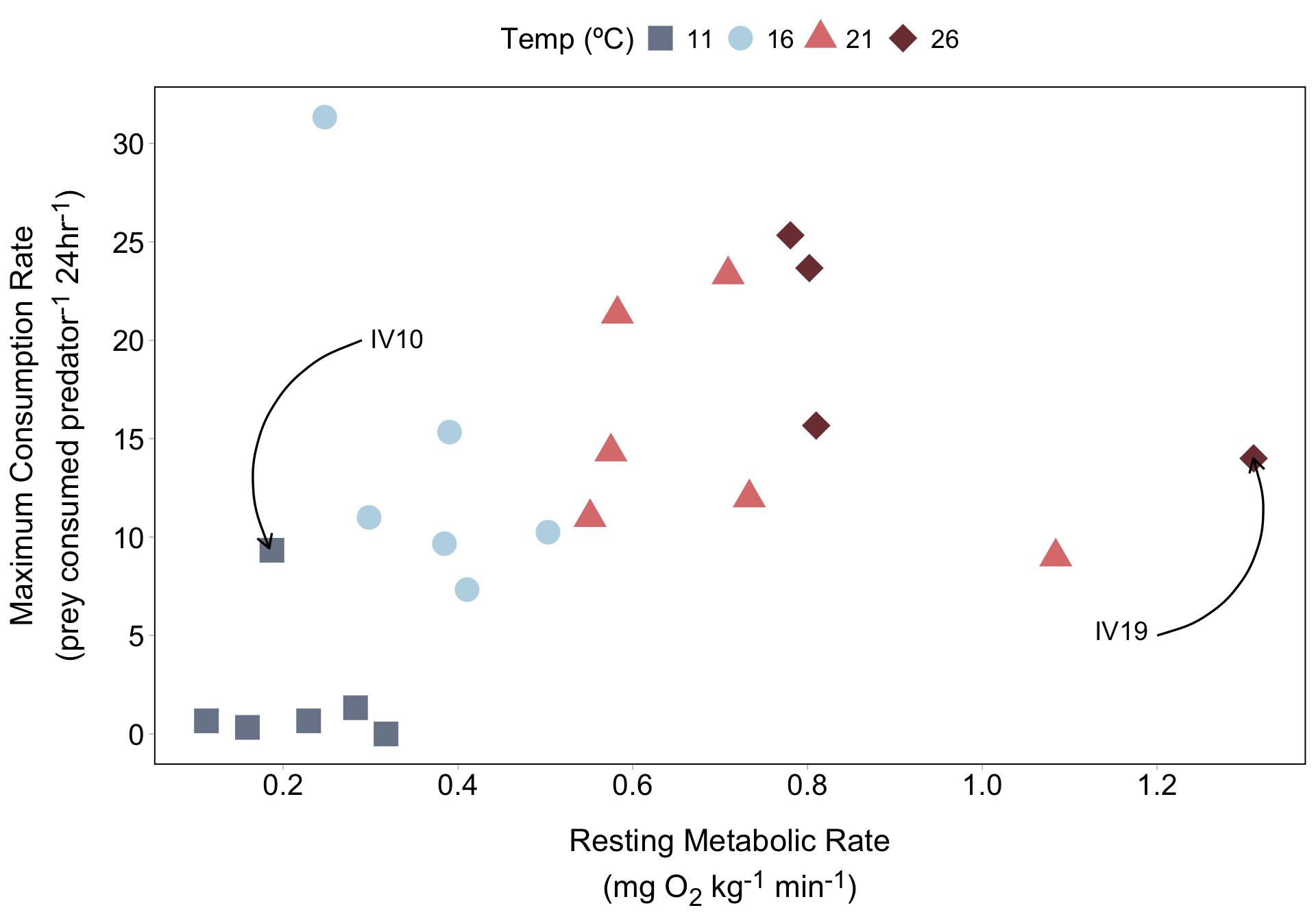
If we have just a few lobsters that we want to call attention to, we can use annotate() to label them. Let’s start with lobster IV10:
Your turn! Create another text label and arrow pointing to lobster IV19 (the farthest dark red diamond to the right). You don’t need to choose this exact location for your text and arrow:
05:00
A solution (you may have chosen a different placement for your text and arrow):
lob_plot +
annotate(
geom = "text",
x = 0.3, y = 20.1,
label = "IV10",
hjust = "left",
size = 5
) +
annotate(
geom = "curve",
x = 0.29, xend = 0.184,
y = 20, yend = 9.43,
arrow = arrow(length = unit(0.3, "cm")),
linewidth = 0.6
) +
annotate(
geom = "text",
x = 1.19,
y = 5.25,
label = "IV19",
hjust = "right",
size = 5
) +
annotate(
geom = "curve",
x = 1.2, xend = 1.31,
y = 5, yend = 14,
arrow = arrow(length = unit(0.3, "cm")),
linewidth = 0.6
)
Let’s say we want to call particular attention to the sharp decline in lake surface level between 1941 - 1983 as a result of unrestricted water diversions. Let’s do so using annotate() (note the order of our annotation layers matters!).
ggplot(data = mono, aes(x = year, y = lake_level)) +
annotate(
geom = "rect",
xmin = 1941, xmax = 1983,
ymin = 6350, ymax = 6440,
fill = "gray90"
) +
annotate(
geom = "text",
x = 1962, y = 6425,
label = "unrestricted diversions\n(1941 - 1983)",
size = 3
) +
geom_line() +
labs(x = "\nYear",
y = "Lake surface level\n(feet above sea level)\n",
title = "Mono Lake levels (1850 - 2017)\n",
caption = "Data: Mono Basin Clearinghouse") +
scale_x_continuous(limits = c(1850, 2020),
expand = c(0,0),
breaks = seq(1850, 2010, by = 20)) +
scale_y_continuous(limits = c(6350, 6440),
breaks = c(6370, 6400, 6430),
expand = c(0,0),
labels = scales::label_comma()) +
theme_light() +
theme(
plot.title.position = "plot",
plot.title = element_text(size = 16),
axis.title = element_text(size = 12),
axis.text = element_text(size = 10),
plot.caption = element_text(face = "italic")
)
Mono Lake’s brine shrimp provide food for millions of migratory birds. Abundances are expected to decline if water levels drop below 6,360 feet above sea level. We can provide context by adding a benchmark line and text.
ggplot(data = mono, aes(x = year, y = lake_level)) +
annotate(
geom = "rect",
xmin = 1941, xmax = 1983,
ymin = 6350, ymax = 6440,
fill = "gray90"
) +
annotate(
geom = "text",
x = 1962, y = 6425,
label = "unrestricted diversions\n(1941 - 1983)",
size = 3
) +
geom_line() +
labs(x = "\nYear",
y = "Lake surface level\n(feet above sea level)\n",
title = "Mono Lake levels (1850 - 2017)\n",
caption = "Data: Mono Basin Clearinghouse") +
scale_x_continuous(limits = c(1850, 2020),
expand = c(0,0),
breaks = seq(1850, 2010, by = 20)) +
scale_y_continuous(limits = c(6350, 6440),
breaks = c(6370, 6400, 6430),
expand = c(0,0),
labels = scales::label_comma()) +
geom_hline(yintercept = 6360,
linetype = "dashed") +
annotate(
geom = "text",
x = 1900, y = 6366,
label = "Decreased brine shrimp abundance expected\n(6,360 feet above sea level)",
size = 3
) +
theme_light() +
theme(
plot.title.position = "plot",
plot.title = element_text(size = 16),
axis.title = element_text(size = 12),
axis.text = element_text(size = 10),
plot.caption = element_text(face = "italic")
)