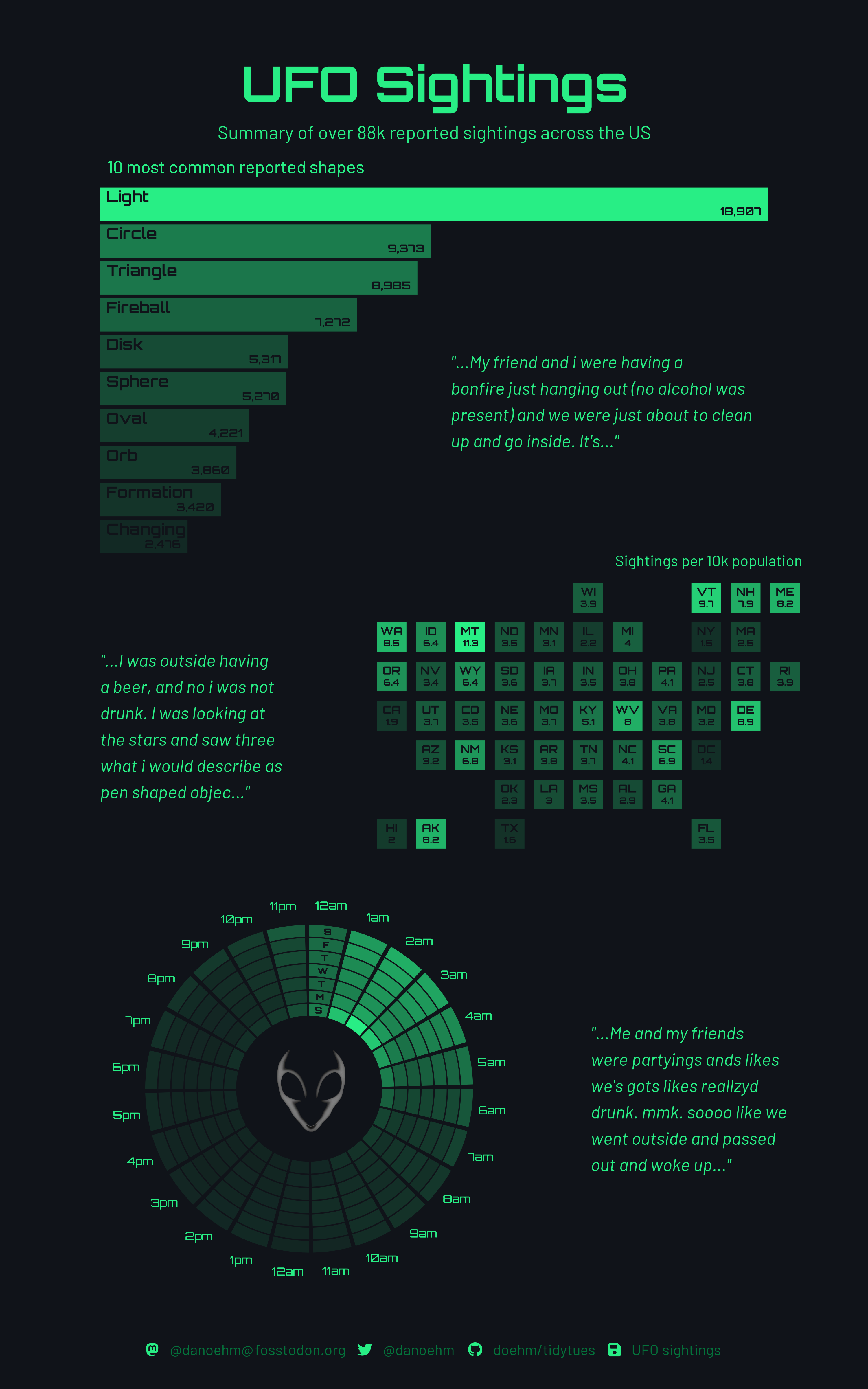
Original viz, by Dan Oehm (original code)
Much of your time as a data scientist will be spent looking at code written by others – you may imagine scenarios such as trying to learn from and adapt someone else’s code for your own work, conducting a code review for a colleague, or validating the code output of a generative AI tool. Being able to look at and make sense of code that you did not write yourself is an invaluable skill and an important one to practice throughout your learning journey. Here, you’ll be asked to interpret data wrangling and {ggplot2} code written by someone else. This will likely require running code (both as a whole and line-by-line), as well as reading documentation, Googling and / or leveraging genAI tools to aid in your understanding.
eds240-hw1-ufo templateFollow these instructions to create a repository from the eds240-hw1-ufo template. The template repository includes HW1.qmd, which is where you’ll be completing your work.
Interpret, explain, and reflect on code adapted from Dan Oehm’s UFO Sightings visualization, following the question prompts in HW1.qmd. You can find metadata and additional information on the rfordatascience/tidytuesday (2023-06-20) readme.md.
Note: While it’s not required or graded, you are strongly encouraged to annotate this code (with the help of documentation, Google, genAI tools, etc.). There’s a lot of creative and helpful code packed into this visualization (and the data wrangling leading up to the viz!), and you may find it helpful to revisit it throughout the quarter to reference particular sections or techniques.
Dan Oehm is the original visionary and creator of this epic TidyTuesday submission from 2023. The code you’ll be annotating for this assignment is a refactored version of Dan’s original code, which was done to reorganize and clarify certain sections for the purpose of this assignment. Refactoring is the process of restructuring (e.g. reorganizing or rewriting) code while preserving its original functionality and output (e.g. the only visual differences in the outputs are the UFO image and plot caption, which were intentionally changed).
Original viz, by Dan Oehm (original code)
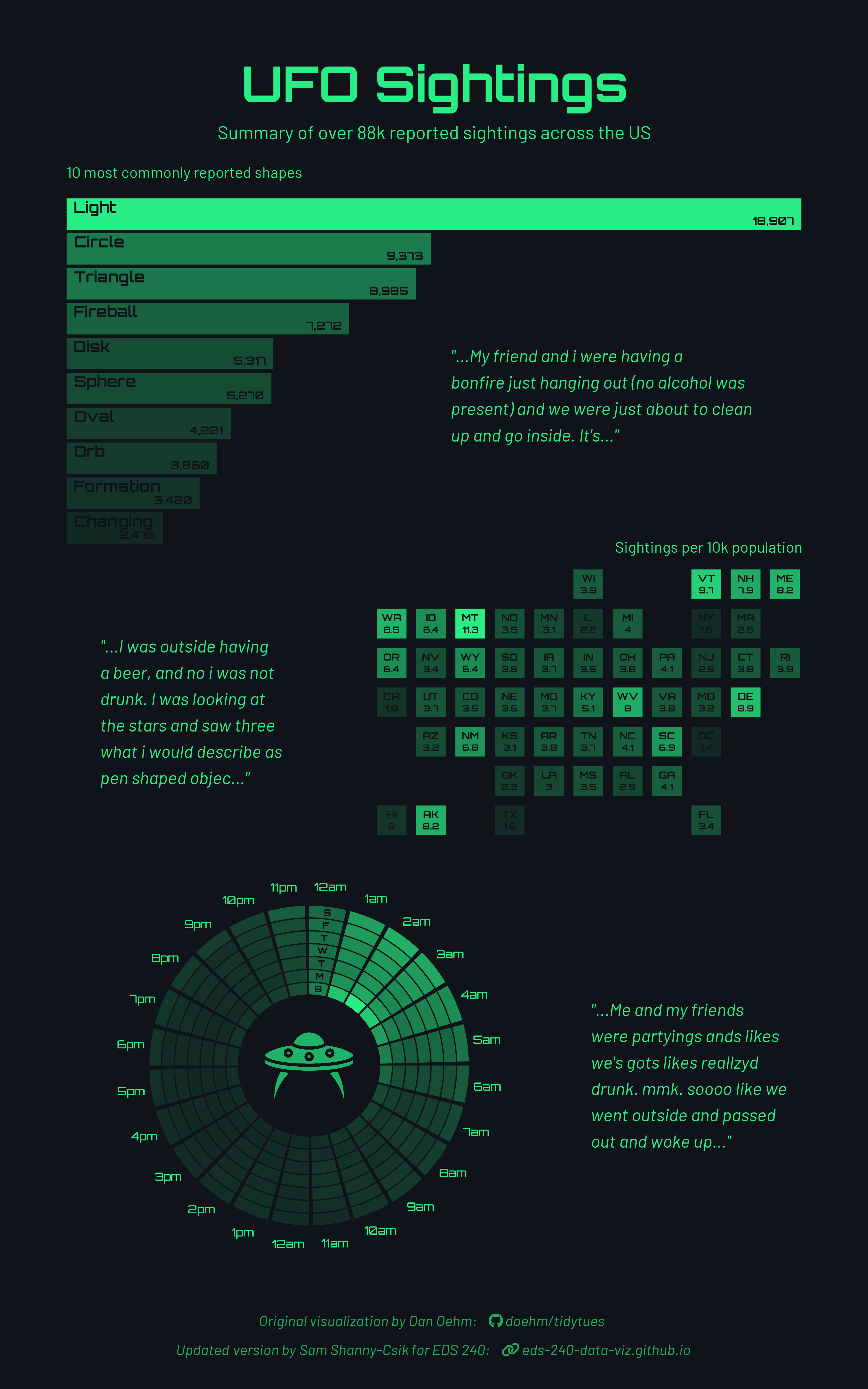
Modified viz, by Sam Shanny-Csik (refactored code)
To enlarge image (in Chrome), right-click on image > Open Image in New Tab
To recieve a “Satisfactory” on HW #1: